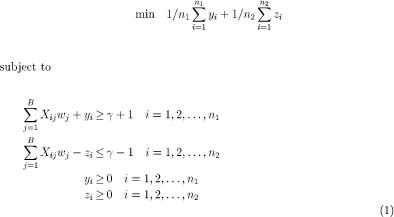Return to GeoComputation 99 Index
Venkat Chalasani and Peter Beling
University of
Virginia, ATTN: Systems Engineering, Olsson Hall, Charlottesville VA 22903 U.S.A.
E-mail: vsc4d@virginia.edu, beling@virginia.edu
To identify a feature of interest we not only have to classify individual pixels as belonging to a specific class such as road, vegetation or water but also identify a set of such pixels as a part of the feature. The problem of assigning an individual pixel a class membership will be referred to as classification, and the process of assigning a set of pixels to a feature will be referred to as feature extraction. During the process of feature extraction certain additional known properties of the feature can be used to reassign the class membership. There has been substantial research done in the past to develop algorithms which identify certain specific kinds of features. The geometrical, radiological or other properties of the specific feature allow the algorithm to be fine tuned to the task at hand.
Roads for example are geometrically elongated, have a maximum curvature, and radiologically have a homogeneous surface and a good contrast to adjacent areas (11). Many road tracing algorithms including edge detection algorithms and mask based approaches depend on these properties for tracking objects. The techniques which track objects by precise outline determination can be referred to as type II operators (7). Other examples are dynamic programming based segment linking systems and knowledge-based systems. These algorithms however do not focus on classification and (with the exception of knowledge-based systems) can only effectively use a single band from an image.
In this paper we propose a two-step process for extraction of roads and demonstrate the results on an Airborne Visible Infra Red Imaging Spectrometer (AVIRIS) image of an area near Williamsburg, Virginia. The first step in our methodology is a classification step in which the bands of the image are treated as attributes. We create a training set by manually identifying certain coordinates as belonging to a specific class, such as road or soil, and then list the attributes for the specific coordinates obtained from the bands of the image. We use the term coordinates to refer to a specific location on a band with reference to the left top corner. We use linear programming to create a discriminating surface between different classes. The linear program is formulated to find a surface that best separates classes. By separating classes one at a time, we can construct a decision tree that can be used to uniquely classify each pixel in the image. Thus our method works like a type I operator which involves classification of individual pixels but is not concerned with precise outline determination.
We use distance to discriminate surfaces for each pixel to assign it a probability measure of being a road, which is then converted to a gray scale value and is used to rebuild the image with only roads. We also show results of a nearest neighbor-based approach for gray scale image creation using linear programming for feature selection. These steps give us a single band image which can be used for road tracing. We demonstrate the use of one such tracing technique, which is based on cost functions and dynamic programming. In the tracing algorithm, certain properties of roads, such as their elongation, contrast to adjoining pixels, and gray scale value, are used to create a cost value. This cost value is low if the configuration of pixels is close to what we would expect from a road, and is high otherwise. We then use dynamic programming to trace a minimum-cost path through the pixels of the image produced by classification. We show that this approach is effective in tracing the roads from the AVIRIS image.
The remainder of the paper is organized as follows: In Section 2, we describe the creation of data sets. In Section 3, we describe our main classification method, which uses linear programming (LP) to build decision trees for classification. In Section 4, we explain how we can carry out feature selection using LP and show how we can use it in our decision tree. In Section 5, we report the results of a nearest neighbor algorithm using features suggested by the LP decision tree. In Section 6 we provide the results of a road tracing algorithm and finally in Section 7, we offer some conclusions and suggestions for further research.
Our training data set was taken from an AVIRIS image of an area south of Williamsburg, Virginia. This image consists of pixels. For each pixel, image intensity is recorded to a precision of 16 bits for each of 224 bands of the electro-magnetic spectrum. The ground resolution of the image is 17m. To enhance the contrast between different features of the image as part of a preliminary visual inspection, we extracted bands 20, 50 and 70 from the AVIRIS image and used them as the red, green, and blue bands of the false-color image shown in Figure 1. Certain features are apparent from the false-color image and from the map shown in Figure 2. One of the major roads is the interstate highway I-64, which runs approximately vertically in the center of the image. The large body of water which is visible to the left is the James River. Other major features include areas of development, such as the portion of Williamsburg seen at the top center of the image, and the large tracks of vegetation or bare soil seen to the right in the image. It seems reasonable, then, to identify four potential classes for each pixel: road, water, soil, or developed area.
Our training set consisted of approximately 150 road points, 400 water points, 1200 soil points, and 200 points of developed area. We created the training data set by manually examining pixels on the false-color image. For each pixel, we recorded the pixel location, associated intensity data for each of the 224 bands in the AVIRIS image, and the most likely class membership for the pixel based on our visual inspection. This procedure is somewhat tedious in general, but often it is possible to identify blocks of pixels that clearly belong to the same class.
For binary tree structures we use the term open node or decision node to indicate a point in a tree where a split or branch is possible. In the case where there are no outgoing branches from a node, the point in the tree is referred to as a terminal node or closed node. The assignment of class to a new point is a simple matter of tracing the point through the tree until the process reaches a node that does not have descendant subsets (i.e., a terminal or closed node). The new point is assigned the class corresponding to the terminal node. For our application, one can define an additional measure that is assigned to each pixel classified as road. This measure, which is obtained by considering the fraction of road pixels to total pixels at each terminal node, represents a probabilistic assessment of the likelihood that the pixel is a road.
Because binary trees grown by CART use only univariate splits, they are relatively bushy (i.e., they contain many branches and terminal nodes). Further, the images created as a result of CART classification also show substantial noise (i.e., they contain many isolated pixels incorrectly classifies as roads). Work by Brown and Pittard (3) shows that classification using multivariate splits, on the other hand, decreases the total number of partitions required in the tree and enhances classification accuracy. One approach to creating multivariate splits is to employ linear programming. The earliest linear programming literature includes a convex hull approach by Kendell (8). Freed and Glover (5) formalized the convex hull procedure to solve a discrimination problem. Further, Glover (6) discusses the issue of a LP null solution, a solution in which the weights associated with the features are all 0, and Bennett (1) provides an elegant formulation which prevents the null solution from occurring. Most of the literature, however, focuses on a two-class separation problem and does not adequately address the issue of multi-class separation. In the remainder of this section we explain how we use a linear programming approach to create multivariate splits and we provide an algorithm to grow a decision tree.
To describe our methodology, let us assume that we have C classes labeled . Let nk denote the number of data points associated with class k in the training set. If there are B bands in the image, the ith data point associated with the kth class in the training set may be described as the collection of intensity values Xkij for . Hence, the dimensionality of the feature space is B.
We formulate a linear program that attempts to separate a set of points belonging to one class (say class 1) from a set of points belonging to another class (say class 2).
The variables in this formulation are wi, yI, zi, and . The variables wi define a hyper-plane that separates (in feature space) the observations of class 1 from those of class 2. If the two classes cannot be cleanly separated some of the variables yi, zi may be forced to take on positive values. The objective is to minimize a weighted average of the errors. The particular choice of weights shown above has the interesting property that it prevents the null hyper-plane wj = 0, , from being selected as the optimal solution (1).
Given the above linear programming technique for creating splits, there are various methodologies that can be used to grow a decision tree for classification. Park (9) also uses linear programming for creating splits. He proposes evaluating multiple splits at each step of the tree growing process, where each split attempts to separate one class from all other classes. This gives C possible splits, where C is the number of classes. The class whose split maximizes the ``gini'' criterion used by CART (2), is chosen to be removed. Thus we have two partitions, one for the split class and the other for remaining classes. Now the partition containing the remaining classes is further partitioned by considering removal of each remaining class one at a time. This procedure is repeated until only one class remains.
We propose a similar methodology except that we choose to split a class whose arithmetic average on the attributes is farthest, in a Euclidean sense, from the arithmetic average of all classes. There are two types of nodes in the tree: split nodes and terminal nodes. Each split node is associated with a linear programming split, as described above, and has two children in the tree, one a terminal node and the other a split node. Each terminal node is associated with a class label, and has no children. An example decision tree is shown in Figure 3. In growing a tree, we maintain a set of active classes (i.e., classes which are not yet associated with a terminal node). Initially, all classes are active. The root node of the tree is always a split node that corresponds to an attempt to separate a single active class from the remaining set of active classes. One child of the root is a terminal node with the class label of the class that we are attempting to separate from the other active classes. The other child of the root is a split node that may be viewed, recursively, as the root node for a subtree with one less active class. At any level of this process, the class that is chosen for separation is that active class whose average pixel intensities are the furthest from the average pixel intensity for all other active classes combined. In the linear programming formulation, the active class we are attempting to separate forms class 1, while class 2 is the set of remaining active classes.
Our tree growing methodology is described formally in Algorithm 1.
We calculate the probability of a particular pixel being of the class road as follows. First we select the discriminating hyper-plane which was used in the decision tree to partition the road class. We calculate the distance from the pixel point to the discriminating hyper-plane. This distance is divided by the centroid distance (i.e., the arithmetic average of distance of all points of the road class from the hyper-plane boundary). If the resulting value is more than 1, we assume a value of 1, constraining the measure to values between 0 and 1. Finally, the gray sale value is obtained by multiplying the measure by 255.
Our first strategy, combined separation, assumes only two classes, road and non-road, to create a gray scale image. Water, soil and developed areas are combined into the non-road class. Results are shown in figure 4. The combined separation strategy is also applied on the image assuming that water is excluded from the non-road class (figure 5). In the second scenario which excludes water, the noise level in the image is decreased. To make this approach useful we can add an additional step in which only water is detected and removed from the image.
Our second strategy, pairwise separation, creates multiple discriminating hyper-planes between road and soil, road and water, and so on. We then add the distance of the pixel to each of the discriminating hyper-planes and divide it by the sum of distances of the centroid of the road class to each of hyper-planes and multiply by 255. In all these cases we use 70 bands and 4 classes to create the decision tree. First we examine the distance to all three classes (water, soil, and developed areas). These results are shown in figure 6. Next we consider distance to soil and developed areas (figure 8), and finally we consider distance to soil only (figure 9). Overall results show that the discriminating hyper-plane for soil is more effective than other discriminating hyper-planes in constructing images. In addition, the pairwise separation strategy is more effective than the combined separation strategy.
We have used this idea in decreasing the computation of the Nearest-neighbor algorithm. We also used this idea to increase the effectiveness of our decision trees. This idea was incorporated into the decision tree by running each split twice. In the first exploratory split we use all 224 bands. We then examine the feature weights and select any features that may have a significantly higher weight than the others. Using this approach we selected two bands that were very effective in separating soil from road. The result of our approach are shown in 10.
The k-nearest neighbor classification algorithm proposed by Fix and Hodges (10) has the following simple form: Define a distance metric on the feature space, say the Euclidean norm, and choose an integer k greater than 0. We have chosen k to be 20. For every point x, find the k points in the training set that are nearest x. These points are called the nearest neighbors of x. Assign x to the class which has the largest representation among the k nearest neighbors of x. This rule can be modified to create the gray scale value that we need. In particular, for each pixel we set the gray scale value equal to 255 times the fraction of the pixel's k-nearest neighbors that belong to the road class.
The k-nearest neighbor algorithm is computationally intensive. In its basic form, this algorithm requires the calculation of the distances between all the points in the training set during each of the k main iterations of the algorithm. To reduce the computations required, we used LP-based feature selection. When we created the LP decision tree we found that 16 of the bands had a much higher coefficients in the discrimination function than the other bands. We created nearest neighbor images using these 16 bands (figure 11), and then compared it with a nearest neighbor image created using 100 bands. There were no substantial differences. Indeed, the results of k-nearest neighbor are similar to our LP-based approach.
We briefly explain the algorithm and provide results. The first step in the process of extracting roads is to characterize the points representing the roads by geometric and spectral considerations. This characterization is done using a costing procedure, that for each pixel, associates a cost such that, the lower the cost, the more likely the point is to be a road pixel. The costing procedure is carried out by examining each pixel's neighborhood to detect special configurations. Certain configurations have a higher probability of being road than other configurations. For example, if in the eight neighborhood of a pixel (eight pixels immediately adjacent to the current pixel) there are only 0 or 1 road pixels then the cost function associated with the current pixel is high, since isolated road pixels are rare. In addition, if we invert our gray scale image, the pixel intensity itself may be used as a cost function. The various cost functions are added together to define an overall cost function, which is used to build a matrix in which each element is a cost associated with an individual pixel.
To trace a road through the matrix, we choose a pixel which we know is a road pixel and choose the number of pixels which should be joined together. Typically the figure is 5 or 6. We can then use dynamic programming to find the minimum cost path through the matrix for any starting point. The results of road tracing on the gray scale image created by our LP decision tree are shown in figure 12.
Future research will involve the modification of our decision tree by using linear programming to create quadratic splits, rather than linear splits. Another avenue of research will explore the modality of the data. If this research shows that the data is multi-modal, our decision tree will be extended to accommodate the data by clustering the data and partitioning each class into subclasses.
 Image using three bands
Image using three bands
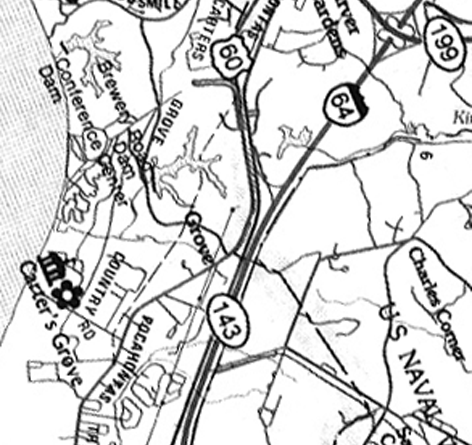 Map of the area
Map of the area
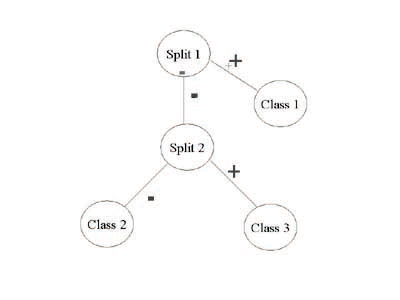 Example decision tree
Example decision tree
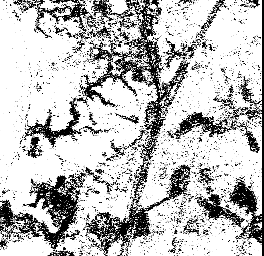 Combined separation
Combined separation
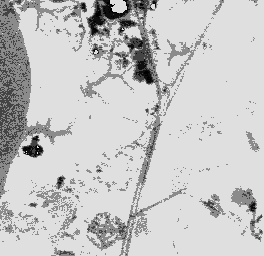 Combined excluding water
Combined excluding water
 Pairwise : distance to water soil and developed area
Pairwise : distance to water soil and developed area
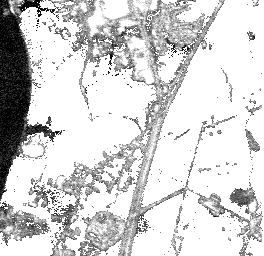 Pairwise Separation
Pairwise Separation
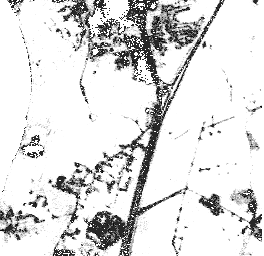 Pairwise : distance to soil and developed area.
Pairwise : distance to soil and developed area.
 Pairwise : distance to soil
Pairwise : distance to soil
 Decision tree results with feature selection.
Decision tree results with feature selection.
 Nearest neighbor results with LP feature selection
Nearest neighbor results with LP feature selection
 Image after road tracing
Image after road tracing
Breiman,L., Friedman, J., Olshen, R. and Stone, C. J.
"Classification and Regression Trees"
Wadsworth 1984.
Brown, D. E., Corruble V. and Pittard, C. L.,
"A Comparison of Decision Tree Classifiers with
Backpropogation Neural Network for Multimodal
Classification Problems" Pattern Recognition
Vol 26 1993.
CPLEX Optimization, Inc. (1995): "Using the CPLEX
Callable Library and Using the CPLEX Base System with
CPLEX barrier and Mixed Integer Solver Options Version 4.0",
CPLEX Optimization, Inc.; Suite 279; 930 Tahoe
Blvd., Bldg 802; Incline Village, NV 89451-9436;
USA; (702) 831-774.
Freed, N. and Glover, F., "A Linear Programming Approach
to the Discriminant Problem" Decision Sciences
Vol 12 1981.
Glover, F., "Improved Linear Programming Models for
Discriminant Analysis" Decision Sciences Vol 21
1990.
Gruen, Li, Agouris, Peggy and Li, Haihong
"Linear feature extraction with Dynamic Programming
and Globally Enforced Least-Squares Matching"
Automatic Extraction of Man-Made Objects from
Aeriel and Space Images 1995.
Kendall, M. G., "Discrimination and Classification". In
P. R. Krishnaiah (Ed.) Multivariate Analysis. New
York: Academic Press, 1966.
Park, Han, C. "An Empirical Study of Methods for Producing
Multi-Variate Decision Trees" Masters' thesis, Systems
Engineering Department, University of Virginia 1995.
Therrien, Charles, W, "Decision Estimation and
Classification". John Wiley and Sons Inc, 1989.