
Issue: Getting it working
Key skill: problem decomposition
So, which do we have here? Well, we can look at the line number flagged by the interpreter, but there's no obviously strange characters there. We need to be a little wary, as sometimes non-UTF-8 characters can include special types of spaces (if absolutely nothing else works, it is always good to delete and replace all your spaces in a line), but it looks like the whole file is just incompatible. For the record, the easiest way of finding non-UTF-8 compatible characters in a file is opening it up in Notepad++ (or something like BBEdit on Macs) and switch the encoding to UTF-8 under the Encoding menu. The characters will turn into little numbered blobs, tofu or mojibake.
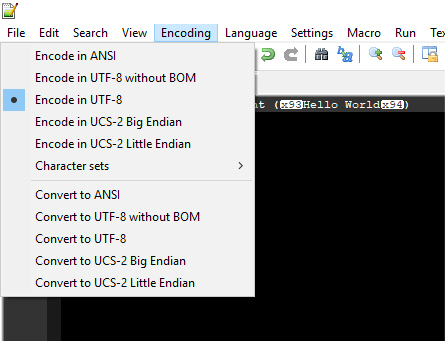
If you see this, you can use Notepad++ to flip between the formats, work out what character the programmer meant, and change them to that: for example, if you set the formatting to UTF-8 and replace the blobs with straight-quotes, Notepad++ won't convert them to smart quotes.
However, as we said, there are no strange characters here, so it must be an incompatible format. As it happens, opening the file in Notepad++, and going to the encoding menu will tell you that it is encoded as "UCS-2 Little Endian". This is nice of Notepad++, because its a hell of a job to tell this programmatically. What can we do about it? Our options are:
- Change the encoding using Notepad++; the encoding menu has an option to Convert to UTF-8 without BOM BOM doesn't generally matter to Python, but without is generally better for most programming files.
- Cut the text from the current file into a new one with a more reasonable encoding scheme; usually basic characters are compatible, or translated.
- Signal the encoding to Python. In theory, if you place the following at the top of the file, it should work:
# -*- coding: ucs2 -*-
Though, frankly, it doesn't seem to for me on Windows; finding a reliable short code for the encoding is quite problematic.
You might have seen that Spyder starts new files with:
# -*- coding: utf-8 -*-
Though this is the default anyhow. - Re-write the file: fine here, but a problem if you've got 300000 lines.
So, all in all, a fairly horrible bug. Sort it out with one of the techniques above, check it works, and then try the shell script again.
- Start
- The problem
- Decomposing the problem
- Testing the parts
- Solving the issues 1
- Solving the issues 2 <-- next
- Final points