Geocomputing with Geological Field Data: Is there a 'ghost in the machine'?
BRODARIC, B.1,2, GAHEGAN, M.1, TAKATUSKA, M.1 and HARRAP, R.3
1 GeoVISTA Center, Department
of Geography, The Pennsylvania State University, USA
2 Geological Survey of Canada,
Canada
3 Queen's University, Canada
Email: bmb184@psu.edu
Key words: Field Data, Geologic Mapping, Self-Organizing Map, Classification, Category Theory
1 Abstract
Bedrock geological mapping, like many field-based activities in the geosciences, involves the construction of a spatial and temporal model of a region via field-based surveys. The geologist interprets the field evidence to constrain possible geologic histories, and constructs hypotheses by combining the field constraints with extant geologic theory. Such reasoning often leads to multiple valid hypotheses since the evidence from field and theory regularly underdetermines the history; consequently there are many valid ways to explain limited data in the Earth's large open system. Because multiple hypotheses can fit the facts, and because the facts themselves are contentious, being somewhat subjective due to the variability of observation and interpretation, geological mappers often regard their skill as an art as well as a science. The encroachment of computer technologies into the field mapping process, and the subsequent availability of digital field data, provides an opportunity to test these claims geocomputationally in order to evaluate the degree of artistry involved in geological mapping.
This study specifically investigates the degree of correlation between field data and the geological classes generalized from them. A study area was chosen where several geologists' data and interpretations were compared, correlated, and contrasted using unsupervised and supervised classification techniques with the self-organising neural map (SOM). Significant challenges in preparing largely qualitative data for the SOM were overcome and are reported. Also reported are correlation results that indicate the geological mapping process is indeed a mixture of abductive (i.e., tacit or intuitive) as well as inductive and deductive reasoning processes. These results lead to broader questions regarding the ability of geocomputational techniques to capture or compute with, the experiential knowledge of agents in field based situations. The results and ensuing questions coincide with field geologists' intuitions that geological classification is partially dependent on the experiential nature of field-based geological surveying and cannot be wholly replicated by computational analogues. This highlights some challenges as well as opportunities for improved geocomputing with human-collected and interpreted field data.
2 Introduction
In traditional bedrock field mapping, geologists go to the field to develop a geologic history for an area. As described by Ady, (1993) this involves "interpreting the three dimensional structure of the rocks and their temporal relationships from their present state in order to construct plausible hypothesis... [T]he geologist must piece together information ... from observations [that] provide the raw data for geologic interpretation." Emphasis is placed on the interpretive element in geological reasoning by many researchers (e.g. Engelhardt and Zimmermann, 1982; Martin 1998; Oreskes, et. al., 1994; Schumm, 1991). Several have attempted to model aspects of the geological reasoning process computationally (Ady, 1993; Flewelling and others, 1992; McCammon, 1994; Simmons, 1983; 1988), including their application to field data (Burns and Remfry, 1976; Sakamoto, 1994). Most agree that the computational challenges posed by geological reasoning are related to geologists operating in open systems. Such systems provide little supporting evidence and generally lead to multiple valid explanatory models, as the field evidence and theory underdetermine the spatio-temporal model (Martin 1998; Schumm, 1991). More specifically, the under-determination results from:
1. Data scarcity, resulting from bedrock unavailability and from unknown underground conditions, i.e., observations are typically limited to areas of exposed bedrock (i.e. outcrop) at the Earth's surface, and must be extrapolated underground into the largely unseen third dimension;
2. Large variable space; only a limited subset of the variable space is available for observation, and a subset of this space is typically grasped by the observer, often from perspectives biased by education and experience; and
3. Changes through time; the history of rock sequences must be defined by extrapolating present states into the past.
Selection of the optimal model often requires reasoning that transcends typical inductive and deductive methods. Inductive and deductive techniques build models from pre-existing concepts in data, or fit data to pre-existing models, respectively, but do not account for conceptual change or the emergence of new scientific concepts. However, the ability to augment scientific concepts is crucial to modeling open systems that appear variable and dynamic. For example, although geological knowledge may be transplanted from one locale to another, the openness and unconstrained nature of the Earth's system rarely reproduces situations exactly (Martin, 1998), requiring existing models to be regularly refined, or new models to be evolved, for new areas. Apart from the irregularity of the physical system, human factors such as the scale or purpose of investigation also point to the need for frequent model revision.
To explain learning in an environment and thus knowledge emergence, philosophic accounts of the scientific process argue that field-based surveying involves at least a third reasoning device, abduction, which synthesizes field information and predisposes humans to best hypothesis selection--and model creation--in the face of sparse evidence (Baker, 1996; 1999; Dott, 1995; Frodeman, 1995; Thagard 1988). This suggests that increased exposure to a situation may trigger abductive reasoning that leads to new knowledge and hence model refinement or creation. Developments in many fields including philosophy (Wittgenstein, 1950; Johnson, 1987; Lakoff, 1987), semiotics (Peirce, 1891), cognitive science (Rosch and Lloyd, 1978), spatial cognition (Mark and Frank, 1996; Mark, et. al. 1999a,b; Tversky and Hemenway, 1983), geospatial interoperability (Frank and Raubal, 1998), and cartography (MacEachren, 1995), lend support to this view, and indicate that some humanly constructed categories, including some geographical, are basically experiential artifacts, resulting from the intersection of the human mind with an environment. Thus, not only is it possible to generate multiple scientific models from the data due to the nature of open systems, but experientialism suggests that it is also possible to develop different (experiential) mental models of a geographical situation (Mark, et. al. 1999b). Moreover, the interaction of scientific and mental models is arguably related to the link between pre-conceptual experience and conceptual processing, though the degree to which these can be demarcated is uncertain (e.g. for a review re: cartography see MacEachren, 1995)
The suggestion that geologic reasoning and model construction is somewhat experiential, leads to questions that ask how much field knowledge can be captured by data or models, and how much can be conveyed using digital knowledge representation techniques? Collaterally, this asks to what degree can we compute with geological (and other humanly collected) field data if some knowledge is human resident--do we need a `ghost in the [geocomputational] machine'? These questions are investigated by correlating the resultant geological categories--i.e. the model--with the recorded field data. Low correlation of data to model may be interpreted as evidence for the experiential thesis (assuming the scientific model is adequate-i.e. that the geologic map works). Indeed, such results are presented later herein.
3 Background
Assessing the correlation between map classes, and between map classes and field data, is related to the estimation of categorical map uncertainty (including error) as might be applied to land cover, soil and vegetation mapping. Categorical map uncertainty is typically grouped into issues of: (1) class identity, (2) class heterogeneity, and (3) class boundary (Apsinall and Pearson, 1994). Class identity uncertainty is concerned with the variability and accuracy of class identification, class heterogeneity uncertainty with the internal variability and accuracy of category description and occurrence, and class boundary uncertainty with the variability and accuracy of map unit boundaries. Although all are relevant to the geological mapping process, and somewhat intertwined, it the first of these that is the focus of this work.
Evaluating the accuracy of map unit classification is generally performed by comparing map classes with field classes or more detailed maps using a confusion matrix that lists misclassification probabilities for pairs of classes (Apsinall and Pearson, 1994); various measures of accuracy can be calculated from such matrices. Shortcomings of the confusion matrix include the expense of field verification, as well as the reliance on one probability for each class over the map area, and its subsequent insensitivity to spatial variation. To overcome this, Goodchild and others (1992) introduce a spatial correlation variable at the pixel level during stochastic simulation for their error model. Bierkens and Burrough (1993a,b) attain spatial continuity through indicator kriging that generates conditional probabilities for prediction and stochastic error estimation.
Although meritorious, these methods are not ideally suited to comparing geological classes with each other or with field data in this study. The confusion matrix requires independent data for comparison that is often unavailable, while the error model and kriging approaches compare overall map error rather than specific class variation. The latter two relate attributes to classes probabilistically understating the impact of the interaction among attributes on classification. Moreover, class confusion is not easily depicted. An alternative approach uses the self-organizing map (SOM), which provides sophisticated classification tools and visualization techniques for class comparison (including confusion). The SOM was used in this study to investigate the process of generalizing classes from geological field data.
4 The Study Area
4.1 Location and Purpose
Geological maps and supporting field evidence were obtained from the Western Churchill NATMAP (National Geological Mapping Program) Project, an active geological survey being carried out by the Geological Survey of Canada. The project is ongoing and is intended to "reveal the character and origin of the Archean greenstone belts of the western Churchill, their mineral wealth and associated granitic continental crust by lifting the veil of Paleoproterozoic" (Western Churchill NATMAP,1999). The project is located in northern Canada, within the political boundaries of the new Nunavut Territory and in the Maquoid belt of the Western Churchill geological province (Figure 1).
Figure 1: the study area. The Western Churchill NATMAP project is located in Northeastern Canada and, in 1998, consisted of 6 1:50,000 map sheets covering an area 60 km x 80 km in the Macquoid geological belt.4.2 Coverage
The geologic maps produced from two summer's fieldwork (1998-99) contain observed and interpreted geologic features located at, or extended to, the earth's surface. These include 16 rock formation regions (i.e. categories) that partition the geographic extents of the surveyed area, macro-scale linear features such as faults or folds, and several thousand critical meso-scale field observations such as rock type, structure or mineral occurrences. Six maps sheets were surveyed at a regional scale of resolution (i.e. 1:50,000), covering a 60 km x 80 km area in the Maquoid belt (Figure 1). The mapping was performed by a team of 15 geologists operating from a common base camp for varying lengths of time. The data from three primary geologists were selected for this study. The selected geologists visited the greatest number of field sites throughout the extent of the survey area and therefore experienced the widest breadth of geologic conditions. In total, they visited 1482 field sites without repetition or overlap, with almost equal distribution of sites per geologist, and fairly equal distribution of geologist sites per class (Figure 2, left). Classes with larger spatial extents were more heavily sampled (Figure 2, right), and each distinct map polygon was sampled; moreover, more than 2/3 of the polygons were sampled by 2 or more of the selected geologists. Hence, the geologists' data were evenly distributed spatially and thematically.
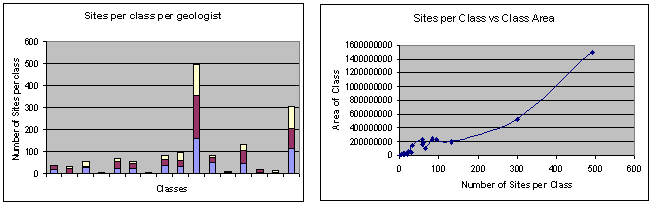
Figure 2: the left panel shows the geologists visited an even number of sites within each class, and the right panel shows that sampling within a class was proportional to the spatial extent of the class.4.3 Data Collection
The collected field evidence consisted of ground truth observations, and it was from these that the geologic history of the area was derived and presented in map form. The field data was collected and managed with the aid of the FieldLog digital geologic field system (Brodaric, 1997), which enforced a common (but customizable) data structure and vocabulary, from the outcrop to the base camp. Hand-held computers linked to GPS aided the digital recording of data on the outcrop (Figure 3). All field descriptions, excluding sketches, were recorded using the hand-held units. In the base camp the FieldLog system assimilated the field data into a GIS environment that employed a relational database system to manage the tabular aspects of the data, and a geologically tailored GIS to manage the cartographic and geographic information portions. The digital field database can thus be seen to represent a set of standardized site-based evidence from which the geologic map categories were generalized.

Figure 3: geologist recording field notes at an outcrop using a hand-held computer.5 Methodology
Field-based category development was investigated by building and visualizing neural representations of the geological field data. Considerable effort was first undertaken to convert the largely textual geological observations to a numeric form representative of the original data and suitable for neural classification. Supervised classification using Learning Vector Quantization (LVQ-Kohonen, 1995), and unsupervised classification using the Self-organizing Map (SOM-Kohonen, 1995), were then utilized to construct the neural representations. These tools were used together to investigate the nature of category separation in feature space, including:
1. Categorical similarity.
2. Categorical similarity between geologists.
3. Categorical evolution through time.
The SOM, LVQ and Sammon mapping techniques are briefly outlined next, followed by a detailed description of the processing undertaken to prepare the field data for input to the SOM and LVQ.
5.1 Self-Organizing Map (SOM)
The unsupervised SOM consists of a matrix of nodes with each node containing a vector of weights. The training phase involve repeated cycles through numeric input vectors to find the nearest node for each and then adjusts that node's weights using a measure of difference between the input signal and the weights (e.g. Euclidian distance). The adjustment is also propagated to neighboring nodes, where the degree of adjustment and extent of propagation may be configured to decay over time. These and other configuration parameters were chosen after significant experimentation.
Once trained a SOM may be labeled with data. Nodes may be assigned multiple labels if they respond to multiple categories, thereby providing a measure of overlap between categories. Because the SOM reflects the topology of the input data (Takatsuka, 1996), visual inspection of a SOM provides a cursory indication of category clustering and overlap, which was useful on occasion. However, because the nodes are arranged at fixed intervals, the relative distances between nodes are not accurate and do not provide a precise measure of similarity. The distance preserving Sammon mapping (see below) was used to determine node and thus category similarity.
5.2 Learning Vector Quantization (LVQ)
LVQ is a modification to SOM to better support supervised learning. In LVQ, a data set of classified data vectors is repeatedly presented to an unconnected set of nodes. The nodes are first initialized with category values and statistically meaningful weights for the category. Actual geological mapped categories were used for this study (e.g. `Baker Lake Group' or `Tonalite--gneissic'). Categories may be apportioned equally to the nodes, or in proportion to their frequency of occurrence in the data. As with the SOM, the nearest node is found and adjusted toward the input vector if their categories match, and moved away from the input vector if the categories mismatch. Note that unlike the SOM, LVQ does not propagate adjustments to other nodes. A time-decay learning rate is defined to control the amount of adjustment applied to each iteration. As with the SOM, configuration parameters were selected after considerable experimentation. LVQ was used to provide an indication of category separation by visualizing the classified vectors via the Sammon mapping (see below).
5.3 Sammon Mapping
The Sammon mapping (Sammon, 1969) transforms an n dimensional vector space into a vector space of lesser dimension, preserving relative vector distance but not topology: i.e., relative distances between vectors in the higher dimension are replicated in the lower dimension, but the shape of original clusters may be deformed. For visualization purposes the n dimensions of the input vector space (the feature space) are transformed into a two-dimensional plane suitable for visualization. Figure 4 (later) shows examples of this when visualized. This transformation enables category similarity and cluster presence to be determined once the nodes are labeled, as similar vectors and hence categories should be nearer to each other. Overlapping categories and multi-labeled nodes signify similar input data. They may also signify an inability on the part of the SOM or LVQ to partition the input data according to the given categories. A Sammon view that lacks clustering is indicative of these problems.
5.4 Attribute Preparation
Inductive neural approaches such as SOMs are patterned after a neurological signal-response model in which an internal configuration of nodes responds to input channels carrying signals of varying amplitude. The input signals are pre-conceptual and concepts are created through stabilization of the internal configuration after repeated exposure to input data. This has proven to be optimal for pattern recognition from signal data (e.g. voice recognition) but proves problematic when incoming data is laden with knowledge beyond a simple amplitude measure. In such cases the incoming knowledge representation scheme must be explicitly recognized, and devolved to a vector of supposedly independent signals for input to a SOM. The devolution of site data to a linear vector is particularly vexing as exploratory field activity may result in a web of relations, where any datum may be related to many others at the same site or between sites (Giles, 1995). Yet, if the meaning of concepts is lost during devolution then any results from subsequent processing must be questioned; hence, adequate and explicit representation of the incoming knowledge is critical to the successful implementation of a SOM.
The SOM or LVQ net must be presented with a string of numbers that represents a point in the input vector space (i.e. so called feature space), where each number in the string represents a value along an axis within this space. Significant challenges were posed in converting the unorthodox field data for SOM/LVQ input. Although the input data possessed typical data types (i.e. interval, ordinal and ratio) it predominantly consisted of more complex attribute domains that were arranged hierarchically or were multi-valued, and which reflected qualitative geological observations. Moreover, these attribute domains were arranged according to a data model that required devolution for input to the SOM. Hence, appropriate preparation of the attribute data types and data model was crucial for successful implementation of the SOM and LVQ; this treatment is discussed in detail in the Appendix.
6 Results
Supervised classification accuracy was highest when certain compositional (i.e. rock type descriptions) and dispositional (i.e. structural measurements) information were considered, and conversely, when certain attributes and samples were ignored. This reinforces the theoretic supposition that certain portions of the input data are more relevant to categorization than others. Apart from indicating that (1) data and samples possessed varying categorization significance, classifying the data with respect to various combinations of geologic category, geologist and time, also demonstrated that (2) categories overlap, (3) individual styles of categorization exist, and (4) categories evolve through time. These results can be summarized as:
(1) Categorization significance: not all data are equally important to categorization, as some attributes and some samples are more significant than others. Varying supervised classification accuracies support this inference (Table 1).
(2) Category overlap: the categories are not wholly delineated within the data. Visual inspection of supervised (Figure 4) and unsupervised (Figure 5) classification results indicates a significant degree of overlap between categories. Both supervised and unsupervised classification results occupied three distinct areas in feature space, each characterized by one of three main rock composition types: plutonic, volcanic, and sedimentary. Overlap is evident in all areas and is implicitly portrayed in Figure 4 via the lack of clustering by color (with each color denoting a unique category); category overlap is explicitly depicted in Figure 5 by the substantial presence of white nodes. Significant category overlap is also suggested by the low supervised recognition accuracies in Table 1, and reinforced by the high unsupervised recognition accuracies of Table 2, which indicate an accurate representation of the input data, and its overlap, in the unsupervised feature space. The geological explanation of the overlap argues that it is difficult to accurately observe the dominant rock composition in complex terrain, though it would appear to become easier with increased exposure to, and thus greater scientific knowledge of, the study area (see result 4 below).
(3) Subjectivity: individuals imposed personal imprints on overall categorization and on individual categories. Though individuals were observing the same terrain and sharing the overall category definitions, distinct individual data trends were evident across all categories (Figure 6) and within individual categories (Figure 7). Figure 7 depicts the complete feature space as viewed by each geologist. Note that the geologists' observations revealed overt data similarities and differences, possibly due to varying geologic conditions or subjective predispositions related to experience, education, expertise, etc. Figure 8 demonstrates this trend is not simply holistic, but occurs within a single category, as pair-wise comparisons of the geologist's observations for the category showed marked differences among the geologists, and also illustrated unique personal trends. Nonetheless, virtually all data for the category were found in a single region of feature space, indicating that broad understanding of the category was shared, even though individual characterizations somewhat differed.
(4) Category evolution: categories evolved through time. Figure 8 illustrates two categories differentiated through time by one geologist: red and blue represent the distinct categories with gray indicating category overlap. The upper and lower left portions depict the state of the two categories at early and later time periods, respectively, where the categories are distributed in two areas of feature space for each time period. Note that in the earlier time period the categories overlap in both areas of feature space, whereas in the later time period the overlap is significantly reduced, indicating category understanding has evolved (white nodes should be ignored as they represent data from other geologists). The right side of Figure 8 supports this claim, as the upper right map demonstrates that the data was spatially distributed (colored dots depict later data and white dots earlier data), hence separation was not due to spatial correlation effects; moreover, the lower right map segment indicates that the cause for delineation may be attributed to concentrated re-investigation of the spatial boundary between polygons, indicating knowledge emergence. Also, the learning rate for categories was variable, as the two categories continued to overlap with other categories (not depicted in the Figures). The significance of this result rests in its support for the notions of category evolution, learning and knowledge emergence. It suggests that experience (i.e. field exposure) is a vital ingredient to geoscientific category formation.
6.1 Category Overlap: Supervised Classification (LVQ)
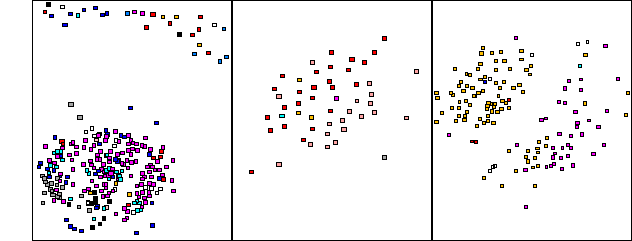
Figure 4: a Sammon mapping of supervised classification results. The data occupies three distinct areas in feature space characterized (left to right, respectively) by three main rock composition types: plutonic, volcanic, and sedimentary. Individual classes are color encoded. Significant category overlap is visually evident in all areas, and substantiated by the low recognition accuracies in Table 1 below.
|
|
|
|
|
|
| Dominant Lithology |
|
|
|
|
| Dominant Lithology and Planar Structural Features |
|
|
|
|
| Dominant Lithology and Planar Structural Measurements |
|
|
|
|
| Dominant Lithology and Structural Measurements |
|
|
|
|
| Lithology |
|
|
|
|
| Lithology and Structural Measurements |
|
|
|
|
Table 1: Recognition accuracy for supervised classification using 500 nodes and 2500 training cycles. Six different configurations (i.e. data types) of the complete data set were evaluated (see section 11.3 for more details). The training accuracy utilizes all samples available with the data type, whereas the test accuracy reflects the average classification results when the data type was randomly partitioned into test and training parts, 3 different times per data type.6.2 Category Overlap: Unsupervised Classification (SOM)
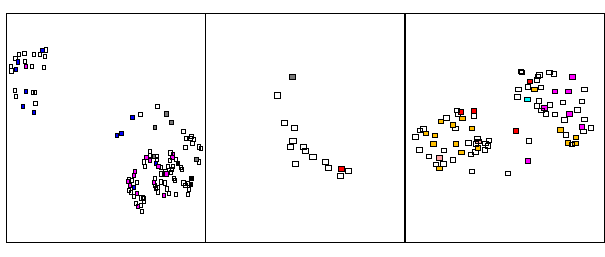
Figure 5: a Sammon mapping of the unsupervised classification results; these also occupied 3 distinct areas in feature space (as in Figure 4). Individual classes are color encoded, where empty (white) nodes represent class overlap, which is substantial. Table 2 below indicates this is an accurate representation of the input data.
|
|
|
|
|
|
|
| Dominant Lithology |
|
|
|
|
|
| Dom. Lithology and Planar Structural Features |
|
|
|
|
|
| Dominant Lithology and Planar Structural Measurements |
|
|
|
|
|
| Dominant Lithology and Structural Measurements |
|
|
|
|
|
| Lithology |
|
|
|
|
|
| Lithology and Structural Measurements |
|
|
|
|
|
Table 2: recognition accuracy for unsupervised classification. Unsupervised classification permitted multiple class labels per node; classification was successful if the test class matched any of the node labels. The ratio q/r represents the mean average distance from nodes to training samples divided by feature space radius. Low q/r and high test accuracies indicate the data was accurately represented in feature space by the SOM. The following SOM configuration was utilized: 20x20 node; 1000 and 60000 training cycles; 16 and 5 radii; 05 and .03 training rates; hexagonal topology; bubble propagation.6.3 Subjective Experience

Figure 6: three views of a SOM, each labeled according to an individual geologist. This shows the 3 geologists possessed some distinct overall categorical trends in observing the same terrain: green, red, blue represent distinct geologist's data, grey represents all remaining data from the other 2 geologists, and empty (white) nodes are unused. Note that although the geologists agreed on the resultant categories, their understanding of the categories varied, possibly due to varying geologic conditions or subjective predispositions related to experience, education, expertise, etc.
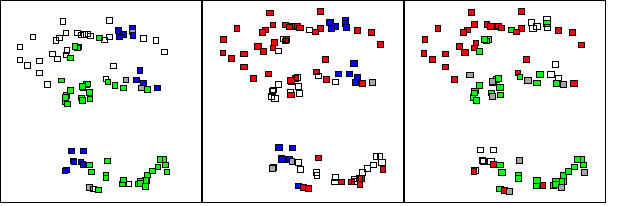
Figure 7: three views of a Sammon mapping, each depicting the pairwise comparison of 2 geologists view of a single category in feature space. Red, blue and green represent distinct geologist's data and grey represents overlapping data nodes in feature space; empty (white) nodes represent the outstanding geologist's data. Note that visible personal trends are evident.6.4 Category Evolution
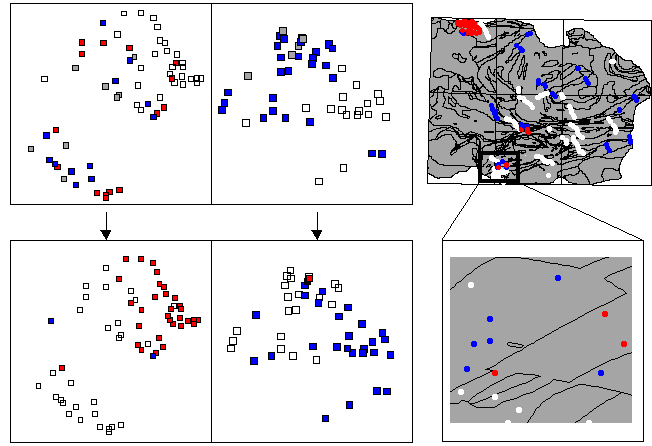
Figure 8: category evolution through time. See text section 6(4) for details.7 Discussion
The most significant implication arising from the foregoing results is the notion that the data, as structured, did not fully embody the developed categories. This implication is supported by the overlap of categories, by their evolution, and by their varied understanding by distinct individuals.
7.1 Category Overlap
Overlap between some categories remained evident even at later stages of the fieldwork. Overlap may be attributable to incomplete data or to an incomplete scientific model:
The issue of data completeness in an open system is daunting, as knowledge in such systems is at best imperfectly available, measurable or recognizable, causing crucial evidence for category discrimination to be lacking. For example, categories with similar rock compositions and dispositions may be separated by their relative age, which cannot be determined in all locales. In Earth Science reasoning, data gaps such as these lead to multiple working models (Chamberlain 1890; Oliver 1998; Schumm 1991) that explain (more or less) the data at hand.
Overlap may also be attributable to an incomplete evolving scientific model, or competing models, where model-based understanding is insufficiently evolved or too divergent to evaluate observations: e.g. in the study data, this might translate into the inability to accurately determine the dominant composition in variably composed terrain. An evolved scientific model will provide greater guidance to the data recording process and hence to categorization. This is illustrated by the results in that some categories became differentiated only after a learning period--after advanced model development.
7.2 Category discrepancy
Individuals possessed varying data perspectives on a category, yet generally agreed on its meaning. This subjective element argues for human factors affecting category definition: for example, experience, culture, expertise, education, and interest may all predispose the categorization process and the data recorded. In this sense the recorded data is a rendition of a mental model, and it brings to question the ability of symbols (i.e. digital data) to possess and convey meaning arising from a mental model. Experiential cognitive linguists (Johnson 1987; Lakoff 1987; Lakoff and Johnson, 1980) and some semiotic philosophers (e.g. Rustrof, 1997) argue that meaning is derived from humans interacting with the environment, and that shared meaning is the product of a common biophysical structure and a common process operating in a shared environment. If symbols are indeed interpreted by cognitive process, then meaning is generated by humans and only prompted by symbols, not resident within symbols, placing seemingly insurmountable barriers to the symbolic processing and representation of full meaning.
Semiotic explanations of the geoscience categorization process adopt this mentalist viewpoint, where categorization is described as an interpretative process called semiosis: scientists use their mental models to evaluate the symbols generated from perception of geoscientific phenomena, and these lead to further interpretations, etc., which eventually tend to converge on one or more best interpretations (Baker, 1996; 1999). Semiosis is related to metonymic and metamorphic reasoning (Lakoff and Johnson, 1980; Lakoff, 1987), where an interpretation (i.e. a category) is reached through the associative traversal of intermediary categories that are locally related (e.g. A->B->C, etc.), but may be regionally disjoint. In these forms of reasoning, it is possible for individuals to exhibit distinct category characteristics that converge to a central region (Lakoff, 1987).
Semiotics blurs the lines between mental model, physical process and symbolic representation, and advocates that understanding arrives from the relations held between these three foundations (Noth, 1990)--with each contributing to the meaning of a category; furthermore, reasoning and learning are derived from the interaction of such triadic relations, as one meaning leads to another. Symbolic representation then constitutes but one of the three important pillars supporting the edifice of human understanding and meaning--and on its own is insufficient. This does not discount the possibility that some forms of symbolic representation may be better suited to certain problem domains than others--i.e. it does not discount a cartographic theory that accommodates human interpretation of map symbols--but it does cast doubt on the efficacy of symbolic representation and reasoning when unmediated by humans (MacEachren, 1995).
Humanly constructed categories can therefore be only partially represented by symbols in this experiential-semiotic view, as experientially constructed mental models and resultant interpretations may (and do) differ. This crisis of symbolic representation leads to a fundamental question here: were individuals unable to symbolically express similar concepts, or did their mental models diverge at local but not regional (mental and spatial) scales? The former is a lexical problem: i.e., were the shared taxonomies variously understood and applied? The significant effort spent in standardizing terminology argues against the hypothesis that category discrepancy resulted from taxonomic or operational lexical ambiguity, and supports the notion that the mental models varied. The degree of similarity between mental models may then account for the extent of shared meaning and/or the degree of difference, explaining why individuals agreed on overall category definitions, yet varied in their individual perspectives of a category.
7.3 Category evolution
The fact that categories were learned and that they changed, indicates that categorization was influenced by factors beyond those recorded in the data itself. The most obvious candidate for such an influencing factor is a scientific model, and in open systems (such as the Earth's) more than one competing scientific model may fit the data. The learning process can then be explained as a reduction in the number of such models fitting the data, and ultimate convergence to a single model. The degree to which this single model is pre-existing (i.e. applied elsewhere), and the degree to which it is unique to the study area, measures the deductive or abductive nature of the categorization process. Deductively, certain facts fit certain model traits best, causing it to be selected--though often this requires a pattern to be inductively confirmed prior to model selection (Brown, 1996); abductively, the rules and facts are created simultaneously, via a creative spark (Josephson and Josephson, 1994; Thagard, 1988).
These distinctions provide incentive to distinguish two terms hitherto used somewhat interchangeably: scientific models, which are primarily theoretic, and mental models, which have been described above as being experiential. The former encompasses laws, rules and theories of science, is amenable to deductive reasoning and symbolic expression (Thagard, 1988), and in terms of cognition is associated with conceptual processing. The latter, mental model, is primarily pre-conceptual and concerned with ordering perception and developing structures utilized by cognitive (symbolic) processes (Lakoff, 1987); it is thus abductive and corresponds to tacit geoscientific knowledge (Loudon, 2000). Such knowledge provides a framework for both containing pre-conceptual knowledge (that is tacit, intuitive, or rule-of-thumb knowledge) and then reasoning with it. For geoscientists this may be exhibited by a holistic understanding of the interaction of geologic variables encountered in the field such as pressure, temperature, composition, disposition and temporal relations, in which comprehension of the whole exceeds the sum knowledge of its parts (e.g. Minsky1986). Category evolution and learning may thus result from the force of this abductive process where pre-conceptual ordering of variables in the field eventually crystallizes into concepts that impact the developing scientific model.
The relationship between the pre-conceptual and the conceptual is unclear. Debated is the degree to which knowledge emergence is resultant from various types of scientific conception (i.e. model-based reasoning--various in Magnani, et. al.,1999) or pre-conceptual scientific understanding (i.e. experiential abduction). The question does lead to significant geocomputational questions, as geoscientific reasoning is described as being composed of deductive, inductive and abductive parts (Baker 1996; 1999; Dott, 1998; Frodeman, 1995; Engelhardt and Zimmermann, 1982). For example, how should we compute with multiple, simultaneous and evolving hypotheses, and how can we take into account the holistic, experiential knowledge resident in the mind?
7.4 Experiential Geocomputing
The preceding discussion implicitly argues that accurate data classification was impeded firstly by knowledge representation architectures that disregarded the scientific and mental models underlying the data, and secondly, by (non-abductive) reasoning processes that did not account for conceptual change and knowledge emergence, nor for the integration of multiple scientific and mental models.
The geocomputational issues derived from this analysis must therefore be concerned with representing and reasoning with dynamic knowledge that is somewhat derived experientially, and which might fit multiple valid scientific and mental models. Geocomputational reasoning mechanisms and systems must thus include deductive, inductive and abductive techniques, and must accommodate the interplay between evidence and multiple valid models in order to capture the full range of knowledge activities involved in scientific explanation (see Gahegan, et. al., 2000; this issue). However, as semiotic and experiential meaning is a marriage of both function and form (Noth, 1990; Thagard, 1988), appropriate reasoning mechanisms must work in tandem with adequate knowledge representation techniques. Indeed, the unexplained portion of the categories in this study signifies a crisis of representation as well as reasoning: how to represent both conceptual and experiential knowledge for geocomputational reasoning?
Knowledge representation for geospatial computing has shifted from operational to ontologic approaches, migrating from the design of data structures and algorithms to the search for, and representation of, fundamental space-time concepts (Goodchild, 1992). The advent of geocomputation may signify a return to operational concerns, but are gains in ontologic form being heeded? This question is reminiscent of the quest in AI (Artificial Intelligence) to merge form with function, and thus integrate various knowledge representation approaches (e.g. Smolensky, et. al., 1994; Sowa, 1999), including:
1. Ontologic: ontologic knowledge is the cataloging of facts, relations, and possibly functions, in symbolic form (Dreyfus, 1972). Semantic relations connect symbols to concepts (e.g. semantic networks), and reasoning is usually deductive (e.g. expert systems). Ontologic structures provide a means for contextualizing data within scientific models, but must contend with semantic issues that arise from the inadequacy of symbols to fully encapsulate meaning. This prevents the differentiation of geospatial categories that are defined, say, operationally rather than conceptually (e.g. via usage--Kuhn, 1994; Riedemann and Kuhn, 1999). Improved semantics may arise from basing space-time ontologic knowledge on cognitive structure (e.g Mennis, et. al., 2000; Usery, 1993), and thereby initiating a symbolic link between scientific and mental models. As a separate concern, space-time ontologic approaches must accommodate multiple interacting models, and thus must provide explicit representation not only of models but also of meta-models (e.g. Bennet, 1997; Raper, 1995).
2. Operational: operational knowledge results from the dynamic interaction of internal, non-symbolic structures (e.g. Chanddrasekaran, 1994; Sun, 1997), where concepts are procedural artifacts not externally recognizable (e.g. neural networks), and where reasoning is typically inductive. Such systems disregard any expert knowledge in the input data (Edelman, 1987), and presume to re-construe knowledge during operation. Yet, humanly collected and interpreted data comes imbued with knowledge that is pertinent and significant. A geographical victim of this practice is the sample description, which is stripped of any empirical relations held within and between samples, and which is removed from the scientific models that give it context. Moreover, model building is confined to a fixed attribute space, which precludes major conceptual change (Booker, et. al., 1994).
3. Experiential: experiential knowledge representation involves the cataloging and indexing of experience. Concepts and relations are dynamically created or eliminated in response to external stimuli. Neural forms of experiential representation downplay conceptual processing and are non-symbolic (Edelman, 1987, 1989; Iran-Nejad, 1987; Schank, 1982), whereas hybrid efforts explicitly model concept formation and knowledge emergence via dynamic ontologic structures that derive from abductive reasoning (among others; French, 1995; Josephson and Josephson, 1994; Thagard, 1988).
The dynamic, competing and conflicting state of scientific categories, and thus of scientific and mental models, suggests a need for experiential computing. This implies a need to develop formal and practical ontologic representations of space-time scientific models and possibly mental models, as well as a means of ordering external experiential stimuli into appropriate conceptual entities that may then activate conceptual processing and thus scientific model evaluation and refinement. Although the mind's full knowledge may be unobtainable, fashioning our geocomputational tools to emulate (as much as is feasible) the scientific and mental nature of the field surveyor should lead to more sophisticated space-time computing, particularly with data that is humanly collected. It is unclear to what degree such computing would be independent of the human expert, but it is imaginable that human involvement could be graded. Aside from field applications, experiential approaches could benefit human directed exploration of data, such as visualization, in which experiential systems could provide ontologic and operational structure to the development of geoscientific and other geographic models.
8 Conclusions
The inability of both supervised and unsupervised methods to fully emulate geological map category formation raises many questions regarding scientific cognition and geocomputation. The results indicate that geological field inquiry is rather more complex than the utilized geocomputational mechanisms would expect, and altogether more complex than current data capture methods might allow. Some might question whether experiential field data can be captured at all, whether our lack of knowledge about the integration of the scientific and mental processes is too great, and whether our knowledge representations are too shallow. This not only indicates a need to enhance the geocomputation of humanly collected scientific data, but it also confirms the value of geological fieldwork, and suggests that fieldwork should remain a vital and irreplaceable part of the geoscientific method. The `ghost in the [geocomputational] machine' may currently haunt us, but only as a barely perceptible and faint apparition that must be brought to life.
Future work includes revisiting the study data to determine the degree to which the mental model versus scientific model affected the categorization process. Longer term plans involve the development of representation frameworks for experiential data and its geocomputing.
9 Acknowledgements
Support from several agencies including the GSC (Geological Survey of Canada), the USGS (U.S. Geological Survey), and NIMA (National Imaging and Mapping Agency) made this work possible and is greatly appreciated.
10 References
Ady, B. (1993). Towards a theory of spatio-chronological relations for geoscience. Masters Thesis, University of Toronto.
Aspinall, R., and Pearson, D.M. (1994). A method for desribing data quality for categorical maps in GIS. Proceedings /MARI'94, volume 1. Fifth European Conference and Exhibition on GIS. EGIS Foundation, Utrecht, p.444-453.
Bennet, D.A., 1997, A framework for the integration of geographical information systems and modelbase management. International Journal of Geographical Information Systems, 11, 4, pp. 337-357.
Baker, V. (1996). Hypotheses and geomorphological reasoning. In Rhoads, B.L. and Thorn, C.E. (Eds.) The scientific nature of geomorphology. Wiley, New York, 57-86.
Baker, V. (1999). Geosemiosis. Geological Society of America Bulletin, 111(5), 633-645.
Bierkens, M.F.P., and Burrough, P.A. (1993a). The indicator approach to categorical soil data. I. Theory. Journal of Soil Science, 44, 361-368.
Bierkens, M.F.P., and Burrough, P.A. (1993b). The indicator approach to categorical soil data. II. Journal of Soil Science, 44, 369-381.
Booker, L.B., Riolo, R.L., and Holland, J.H. (1994). Learning and representation in classifier systems. In Honavar, V. and Uhr, L., (Eds.) Artificial Intelligence and Neural Networks: Steps toward principled Integration. Academic, New York, p.581-614.
Burns, K.L., and Remfry, J.G. (1976). A computer method of constructing geological histories from field surveys and maps. Computers and Geosciences, 2, p.141-162.
Brodaric, B. (1997). Field Data Capture and manipulation using GSC Fieldlog v3.0: DIGITAL MAPPING TECHNIQUES '97 - Proc. of a workshop on digital mapping techniques: methods for geologic map data capture, management and publication, USGS Open File Report 97-269, p.77-82.
Brown, H.I. (1996). The methological roles of theory in science. In Rhoads, B.L. and Thorn, C.E. (Eds.) The scientific nature of geomorphology. Wiley, New York, 3-20.
Chamberlain, T.C. (1890). The method of multiple working hypotheses. Science, 15, 92-96.
Chandrasekaran, B., and Josephson, S.G. (1994). Architecture of Intelligence: The Problems and Current Approaches to Solutions. In Honavar, V. and Uhr, L., (Eds.) Artificial Intelligence and Neural Networks: Steps toward principled Integration. Academic, New York, p.21-50.
Clifford, H.T., and Stephenson, W. (1975). An introduction to numerical classification. Academic, New York.
Date, C.J. (1990). An introduction to database systems, Volume 1, Fifth Edition. Addison-Wesley, New York.
Dott, R.H. (1998). What is unique about geological reasoning. GSA Today, October, 1998.
Dreyfus, H. (1972). What computers cannot do: the limits of artificial intelligence. Harper and Row,New York.
Dunn, G., and Everitt, B.S. (1982). An introduction to mathematical taxonomy. Cambridge, New York.
Edelman, G.M. (1987).Neural Darwinism: the theory of neuronal group selection. Basic Books, New York.
Edelman, G.M. (1989). The remembered present. A biological theory of consciousness. Basic Books, New York.
Engelhardt, W. and Zimmermann, J. (1982). Theory of Earth Science. Cambridge, New York.
Flewelling, D.M., Frank, A.U., and Egonhofer, M.J. (1992). Constructing geological cross sections with a chronology of geologic events. In Proceedings of the 5th International Symposium on Spatial Data Handling, IGU Commission on GIS, August 3-7, 1992, Charleston, S.C., p.544-553.
Frank, A.U. and Raubal, M. (1998). Specifications for interoperability: formalizing image schemata for geographic space. In Poiker, T.K., and Chrisman, N., (Eds.), Proccedings, 8th International Symposium on Spatial Data Handling, 331-348.
French, R.M., (1995). The subtlety of sameness: a theory and computer model of analogy. MIT, Cambridge.
Frodeman, R. (1995). Geological Reasoning: geology as an interpretive and historical science. GSA Bulletin, 107(8), 960-968.
Gahegan, M. (2000). The case for inductive and visual techniques in the analysis of spatial data. Geographical Systems. 7(1), 113-139.
Gahegan, M, Takatsuka, M., Wheeler, M. and Hardisty, F. (2000). GeoVISTA Studio: A Geocomputational Workbench-- this volume.
Garson, G.D. (1998). Neural networks: an introductory guide for social scientists. Sage, London.
Giles, J.R.A. (1995). (Ed.) Geological data management. Geological Society of London special publication 97. Geological Society of London, London.
Goodchild, M.F., 1992, Geographical Data Modeling. Computers and Geosciences, 18, 4, pp.401-408.
Goodchild, M.F., Guoqing, S., and Shiren, Y. (1992). Development and test of an error model for categorical data. International Journal of GIS, 6, 87-104.
Iran_Nejad, A. (1987). The schema: a long-term memory structure or transient functional pattern. In Tierney, R.J. and others, (Eds), Understanding readers' understanding: theory and practice. Lawrence Erlbaum, Hillsdale.
Johnson, M. (1987). The body in the mind: the bodily basis of meaning, imagination and reason. University of Chicago, Chicago.
Josephson, J.R., and Josephson, S.G., (1994). Abductive Inference. Cambridge, New York.
Kuhn, W. (1994). Defining Semantics for Spatial Data Transfers. Advances in GIS Research: Proceedings, Sixth International Symposium on Spatial Data Handling, 5th-9th Septemer, 1994, Edinburgh, Scotland, 973-987.
Kohonen, T. (1997). Self-organizing maps. Berlin, New York.
Kohonen, T., Hynninen, J., Kangas, J., and Laaksonen, J. (1995). SOM_PAK, The Self-Organizing Map Program Package, version 3.1 (April 7, 1995).
Lakoff, G. (1987). Women, Fire and Dangerous Things. University of Chicago, Chicago.
Lakoff, G. and Johnson, M. (1980). Metaphors We Live By. University of Chicago, Chicago.
Loudon, T.V. (2000). Geoscience after IT: Part J. Human requirements that shape the evolving geoscience information system. Computers and Geosciences, 26(3A), p.A87-97.
Mark, D.M., and Frank, A.U. (1996). Experiential and formal models of geographic space. Environment and Planning B, 23, 3-24.
Mark, D.M., Smith, B., and Tversky, B. (1999a). Ontology and Geographic objects: an empirical study of cognitive categorization. Spatial Information Theory: cognitive and computational foundations of GIS: Proceedings, international conference COSIT'99, Stade, Germany, August. New York: Springer, 283-298.
Mark, D.M., Freska, C., Hirtle, S., Lloyd, R., and Tversky, B. (1999b). Cognitive models of geographic space. International Journal of GIS, 13(8), p.747-774.
Martin, R.E. (1998). One Long Experiment. Columbia University, New York.
Magnani, L., Nersessian N.J., Thagard, P., (Eds.) (1999). Model-based reasoning in scientific discovery. Plenum.
McCammon, R.B. (1994). PROSPECTOR II; towards a knowledge base for mineral deposits. Mathematical Geology. In Expert systems and artificial intelligence in the applied geosciences; 26th international geological congress. (Roussos Dimitrakopoulos, editor and others); 26 (8), November 1994. p. 917-936.
Minsky, M.L. (1986). The Society of Mind. New York: N.Y. Simon and Schuster.
Noth, W. (1990). Handbook of Semiotics. Bloomington: Indiana University Press.
Oreskes, N., Shrader-Frechette, K., and Belitz, K. (1994). Verification, Validation, and Confirmation of Numerical Models in the Earth Sciences. Science, 263, 641-646.
Raper, J.F., and Livingston, D., 1995, Development of a geomorphological spatial model using object-oriented design. International Journal of Geographical Information Systems, vol. 9, no. 4, p. 359-384.
Riedemann, C. and Kuhn, W. (1999). What are sports grounds? Or: why semantics requires interoperability. . In Vckovski, A., Brassel, K.E., and Schek, H.-J. (Eds.) Interoperating geographic information systems. New York: Springer, 217-230.
Rosch, E. and Lloyd, B.B. (1978). Cognition and Categorization. Hillsdale: Lawrence Erlbaum.
Rustrof, H. (1997). Semantics and the body. Toronto: University of Toronto Press.
Sakamoto, M. (1994). Mathematical Formulations of Geological Mapping Process - Algorithms for an Automatic System. Osaka City University.
Sammon, J.W. Jr. (1969). A Nonlinear Mapping for Data Structure Analysis. IEEE Transactions on Computers, C-18, 5, p.401-408.
Schank, R.C., (1982). Dynamic memory: a theory of reminding and learning in computers and people. Cambridge, New York.
Schumm, S.A. (1991). To Interpret the Earth:Ten ways to be wrong. Cambridge, New York.
Simmons, R.G. (1983). Representing and Reasoning About Change in Geologic Interpretation: Technical Report 749. Massachusetts Institute of Technology.
Simmons, R.G. (1988). Combining associational and causal reasoning to solve interpretation and planning problems. PHD Thesis, Massachusetts Institute of Technology.
Smith E.E. and Medin, D.L. (1982). Categories and Concepts.Harvard, Cambridge.
Smolensky, P., Legendre, G., and Miyata, Y. (1994). Integrating Connectionist and Symbolic Computation for the Theory of Language. In Honavar, V. and Uhr, L., (Eds.) Artificial Intelligence and Neural Networks: Steps toward principled Integration. Academic, New York, p.509-530.
Sowa, J.F. (1999). Knowledge Representation: Logical, Philosophical, and Computational Foundations. Brooks/Cole, New York.
Sun, R. (1997). Connectionist models of reasoning. In Omidvar, O.M. and Wilson, C.L., Progress in Neural Networks, Volume 5: Architecture. Ablex, Norwood.
Rescher, N. (1978). Peirce's Philosophy of Science.Notre Dame, London.
Takatsuka, M. (1996). Free-Form Three Dimensional Object Recognition using Artificial Neural Networks. PHD Thesis, Monash University, AU.
Thagard, P. (1988). Computational Philosophy of Science. MIT Press.
Tversky, B., and Hemenway, K. (1983). Categories of Environmental Scenes. Cognitive Psychology, 15, 121-149.
Usery, E.L.(1993). Category Theory and the Structure of Features in GIS. Cartography and GIS, 20(1), 5-12.
Western Churchill NATMAP. (1999). Renewal Application (1999-00). http://www.nrcan.gc.ca/~shanmer/Churchill_NATMAP_renewal.html.
Wittgenstein, L. (1953). Philosophical Investigations. Macmillan, New York.
11 Appendix (Data Preparation)
11.1 Domain Preparation (Hierarchies)
The attribute domains were characterized by complex data types requiring significant preparation, such as numeric conversion and scaling. These types include: partially ordered sets (hierarchies), unordered sets, ordered sets, modal and spatial data types.
11.1.1 Partially Ordered Sets (Hierarchies)
Both physical and social scientists may record information using predefined or evolving taxonomies that are hierarchically organized. The numeric representation of a taxonomy is reasonably straightforward, provided the hierarchy is shallow (i.e., has few levels). In such cases, each branch of the hierarchy is granted a range of digits in which elements at that level are enumerated. These numbers are concatenated from parent to child along the branch to form a hierarchic code. For example, consider the three level branch `Igneous->Granitoid->granite' might be encoded, using one digit per level, as `100->110->111'. Problems arise when hierarchies are long or deep (i.e., have many elements at a level or many levels) in that resulting codes will exceed the computational limits of numeric representation. Complex hierarchies are also problematic in that an element may be classified under more than one parent, reflecting diverse and possibly mixed classification criteria. In this study, the few cases of multiple parentage were resolved pragmatically, by inspecting the data and noting that the context of the data generally favored one parent, which was then selected for encoding. This resulted in straightforward hierarchies where conceptually similar terms were numerically proximal.
11.1.2 Unordered Sets
Unordered sets are assemblages of data elements drawn from a domain. For example, various descriptive or compositional characteristics of a rock type were recorded in the study data as unordered sets: e.g. descriptions (`masssive, homogeneous') or mineral compositions (`biotite, quartz').
Unordered sets such as these may be encoded by projecting the dictionary of terms as individual binary attributes into the SOM/LVQ input vector (Garson, 1998). Consider a vector v1 consisting of k attributes ai, 1<= i <=k, and a mineral attribute m with a domain consisting of d1 to dn terms (e.g. d1 = 'biotite', d2 = 'quartz', etc.), such that v1 = (a1, a2, a3,..., ak, m); then v1 would be transformed to v1*= (a1, a2, a3,..., ak , d1, d2, d3, ..., dn) where di = {0, 1} to indicate absence or presence. Taxonomists (e.g., Clifford and Stephenson, 1975; Dunn and Everitt; 1982) indicate that multi-attribute binary encoding such as this lends itself to representation by a single number (e.g. m = `1 0 0' = 4), obviating the need to project the domain into the attribute space. However, typical 32 or 64 bit numeric representation places an upper limit on the number of terms in the domain that is often insufficient, particularly when n is large or when the span of the di are extended (e.g. di = {0,1,x (unknown)}) or scaled (e.g. di = {0,100}), as was required by the study data. Consequently, the large, scaled attribute domains of the study data required the individual terms to be projected as attributes into the feature space.
11.1.3 Ordered Sets
Ordered sets are sequenced assemblages of data elements. Replacing the binary encoding (i.e. di = {0, 1}) with an ordinal value (e.g. the sequential order, di = {1, ..., n}) permits the binary projection technique to be adopted for sequenced attributes. Although, this may introduce undesirable scaling effects (11.3.6) when the range of di is large, it acts to lessen the potential of semantic conflict (section 11.4) when attributes are numerically discriminated. The extension of this projection method to interval data (e.g., % of abundance) or ratio data (e.g., quantity of abundance), with corresponding adjustments to the values of di, is analogous and straightforward.
It is clear that at most two pieces of information are captured by this method, element presence and some other concept such as sequence or abundance, and it is also clear that 3 or more orthogonal pieces of information are not accommodated (e.g. presence, sequence and abundance: `biotite(20%)-quartz(20%)'), requiring the data to be normalized in the database sense (e.g. Date, 1990) and resulting in multiple occurrences within a sample:
11.1.4 Modal
Modal data are a special case of interval data where the scale is constant but cyclical; e.g., angles, days, aspect, etc. In the study data, the horizontal component of three dimensional orientation measurements was converted from a single polar coordinate (with 0-360 degree scale) to a Cartesian x-y pair to ensure, for example, that 0 and 360 were proximal.
11.1.5 Spatial
A distinctive trait of geographic thought is the notion of spatial correlation--the premise that spatial proximity endows similarity. Spatial correlation may be induced in the SOMs by including the sample location in the input data vector, using some tessellated coordinate encoding to ensure actual nearest neighbors are proximal. The disadvantage of this approach lies squarely in its intent, as inappropriate scaling of the spatial attributes may cause them to dominate classification, resulting in SOMs that reflect the geographic (versus thematic) distribution of the data.
However, spatial correlation was not induced in this study for other reasons, mostly related to the sampling strategy, which aimed not only to provide adequate coverage of the area, but also to sample the spatial boundaries of the classes in order to clearly demarcate them. Spatially correlating these important boundary samples would have had the adverse effect of reducing classification accuracy by inducing unwarranted similarity of these distinct but proximal samples (Gahegan, 2000). Moreover, the regional scale of mapping and related sampling density, combined with the heterogeneity of the (non-linear) physical environment, all argued against introducing spatial correlation effects into the classification process.
11.1.6 Attribute Scaling
SOM/LVQ calculations are sensitive to the scale and thus variance of the input data. They compare input vectors using a similarity measure, typically Euclidean distance, causing attributes with larger ranges and typically greater variance to dominate classification. Performing statistical normalization on all attributes (by subtracting the mean and dividing by the standard deviation) will transform attributes to a common scale and temper overt dominance (Garson, 1998).
Alternatively, weighting functions may be applied to specific input variables, to reflect their relative value to classification. Selecting appropriate weighting factors is rather arbitrary (Garson, 1998; Kohonen, 1995) and exceeds purely inductive, data-driven, approaches, and encroaches on model-based methods, where criteria beyond the raw data exert influence on classification. Such criteria may consist of the laws of science, explanatory models and their exemplar occurrences, as well as rules of thumb and so-called tacit knowledge (Loudon, 2000) accumulated via general experience and from prolonged interaction with a specific study area. As geological mapping involves the construction of a 3d spatio-temporal model for an area, some attributes posses greater classification relevance than others, while the others contribute to the geometric, topologic or age description of the evolving model. The degree of classification relevance is determined both a priori, in a general theoretic sense from the model-based criteria, and in situ, where local factors may refine or supplement theory. Experimentation with the SOM/LVQ demonstrated that appropriate scaling of rock description attributes was one of two main factors leading to adequate classification; the other being successful conversion of the knowledge representation scheme, as discussed above.
11.1 Concept Preparation
The study data was composed of two main concepts, composition (rock type descriptions) and spatio-temporal disposition (structural type and measurement), each possessing several attributes, including an attribute denoting the dominance of the composition. Site descriptions typically consisted of multiple compositions and dispositions, many of which were related (i.e. dispositions were measured within specific compositions). The development a single site signature was required to address multiple occurrences of compositions, dispositions, or their combinations at a site. Signatures for these were obtained by training a SOM with their respective data, and subsequently using the coordinates and error values of the responding nodes to form a signature vector for each set of multiple occurrences.
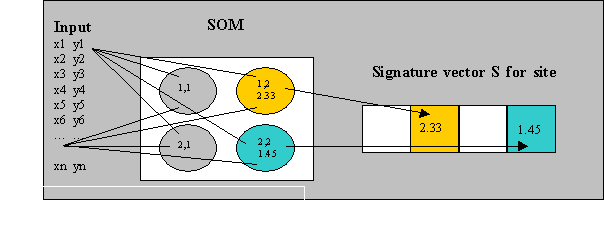
Consider that an n x n matrix of nodes can be linearly represented as an n x n vector by appending columns or rows; then, it is possible to build a signature vector for an input data set by scaling the distance (quantized error) of the responding node and assigning it to the i,jth position of the signature vector (Figure 9). In our case, scaling involved statistical standardization of the responding distance and scaling of the resulting values. To maintain their high influence on classification, dominant compositions were favored with additional scaling and took precedence when conflicts arose at the signature vector.
Semantic conflict occurred when dissimilar concepts (input vectors) converged to the same i,jth position in the output signature vector. Two semantic conflict types were noted: (1) taxonomic and (2) operational. Taxonomic conflict occurred when two or more vectors were conflated to the same output point (i,jth position and value). Operational conflict was an artifact of the data caused by similar occurrences at a site converging to the same output dimension (i,jth position). Few taxonomic conflicts were encountered in the study area (see Table 3), indicating the SOM was adequately configured. Several operational conflicts were encountered indicating similar data were often recorded at a site. Operational conflicts were resolved by prioritizing the dominant composition and otherwise accepting the last conflicting value.Figure 9: preparation of a site signature from multiple samples at a site: input X and Y for site A form one signature S at A.
The total number of sites affected by semantic conflict is presented in Table 3 as the proportion of stations affected. Although this amount is not insignificant, the results also show that the conflicting data were indeed quite similar, suggesting the semantic loss was low and that the affected sites remained adequately representative of the original data.
|
|
|
|
|
|
Semantic Conflict (# sites) |
Semantic Conflict (# sites) |
Semantic Conflict (% sites) |
Mean Conflict Distance |
Feature Space Radius |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 3: results from developing signatures for multiple occurrences at a site for different data types. In the first data type a signature was developed for all structural measurements (i.e. dispositions) related to each specific rock composition at a site; in the second data type, a signature for all rock compositions at a site was developed; and thirdly, a site signature for all rock compositions and related structural measurements was developed. Low ratio of mean distance between semantic conflicts to overall feature space indicates that conflicts occurred between semantically similar data and that the signatures adequately represented the original data.11.2 Data Selection
The construction of a spatio-temporal model for an area requires the collection of field data whose support of categorization may vary. Some of the data might instead support the determination of spatio-temporal relationships, or describe local complexities disjoint with the categorization for an area, categorization being bounded by cognitive and spatial scale. Therefore, some attributes and some samples are more important than others, and the task of a field surveyor may be stated as one of assigning appropriate weighting to attributes and samples.
In order to concentrate on data most relevant to classification, and thus to boost classification accuracy, the study data were apportioned into six derivative data sets. Each derived data set contained an increasing proportion of the original data set, and differed in both the number of attributes and number of original samples retained. The first three data sets did not require site signatures to be developed (as discussed above) whereas the last three did:
2. Dominant composition and dispositions 1: dominant lithology and planar structural feature type (omitting orientation measurements).
3. Dominant composition and dispositions 2: dominant lithology and planar structural measurements.
4. Dominant composition and dispositions 3: dominant lithology and all structural measurements
5. Composition: all lithologies described at a site.
6. Composition and disposition: all lithologies and all structural measurements at a site.