![]()
![]()
![]()
Nevertheless, clustering methods share their needs for user-specified arguments and prior knowledge to produce their best results. Such information needs are supplied as density threshold values, merge/split conditions, number of parts, prior probabilities, assumptions about the distribution of continuous attributes within classes, and/or kernel size for intensity testing (for example, grid size for raster-like clustering and radius for vector-like clustering). This parameter tuning is extremely expensive and inefficient for huge data sets because it demands pre-processing and/or several trial and error steps.
The need to find best-fit arguments in wide-spread semi-automatic clustering is not the only concern, the manipulation of data to find the arguments opposes Openshaw's famous postulation [23] to ''Let the data speak for themselves''. This postulation underpins exploratory spatial data analysis. Hypotheses should be uncovered from the data, not from the user's prior knowledge and/or assumptions. So far, clustering approaches detect relatively high-density areas (localised excesses) within the study region. However, this clustering principle alone has difficulty in determining exactly what is high-density and what is relatively less-density. Thus, it frequently fails to find slightly sparse groups when they are adjacent to high-density groups despite of their great importance for further investigations. We present specific illustrations of these problems in Section 2.
We overcome these problems by precise modelling of spatial proximity in association with density. Density is a natural principle, but it should be combined with relative proximity. Precise modelling of spatial proximity means a capability to obtain unambiguous information about global effects and local effects since geographical phenomena are the result of global first-order effects and local second-order effects [2]. Global effects indicate the degree of excesses in the global sense of view while local effects represent local variations. With the combination of both effects, localised groups shall appear.
Gold [10] argues that the traditional modelling approaches are not able to capture spatial proximity uniquely or consistently for point-data sets. As an alternative, Voronoi modelling has several advantages for proximity relations of points over the conventional modelling based on either vector- like or raster-like modelling. In particular, Voronoi models uniquely represent discrete point-data sets and consistently capture spatial proximity [10]. We show that, as a consequence, automatic clustering is feasible.
Delaunay Diagrams (these remove ambiguities from Delaunay Triangulations when co-circular quadruples are present), as duals of Voronoi Diagrams, are used as the source of our approach. Section 3 discusses the use of Delaunay Triangulation in modelling spatial proximity and in clustering. With this structure, we find clusters by locating sharp gradient changes in point density (cluster boundaries). In our automatic clustering, users do not specify arguments. We believe any parameters must be encoded in the proximity structures of the Voronoi modelling, and thus, or algorithm, AUTOCLUST, calculates them from the Delaunay Diagram. This not only removes human-generated bias, but also reduces exploration time.
The intuition behind boundary finding is that, in the Delaunay Diagram, points in the border of a cluster tend to have greater standard deviation of length of their incident edges since they have both short edges and long edges. The former connect points within a cluster and the latter straddle between clusters or between a cluster and noise. This characteristic of border points is the essence for formulating a dynamic edge-elimination criterion. The criterion has the flavour of a statistical test, labelling edges that are units of the standard deviation away from the mean. However, the principles behind our methods go far beyond this initial intuition and at least two justifications appear in Section 4.
Removal of edges labelled as too long from the Delaunay Diagram is the first phase that extracts initial rough boundaries. This phase takes into account local and global variations to ensure that relatively homogeneous clusters are not broken up into tiny uninteresting sub-sets and relatively heterogeneous sub-sets are segmented into meaningful sub-clusters. Section 4 details this process as well as two subsequent analysis phases in order to eliminate some difficulties with graph-based clustering. This process removes bridges (line-like paths with a small number of points) that connect clusters.
The effectiveness of our approach allows us to detect not only clusters of different densities, but sparse clusters near to high-density clusters. Multiple bridges linking clusters are identified and removed. All this within O(n log n) expected time, where n is the number of data points. We confirm AUTOCLUST's time efficiency and clustering quality experimentally in Section 5. These performance evaluations use both synthetic data sets and real data sets.
We contrast AUTOCLUST with other algorithms for clustering large geo-referenced sets of points. Detailed information can be found in companion technical report [8]. It categorises clustering methods into 6 groups on the basis of their working principles. We discuss their major problems in the light of AUTOCLUST. Finally, we point out some other areas of impact of our approach with concluding remarks in Section 6.
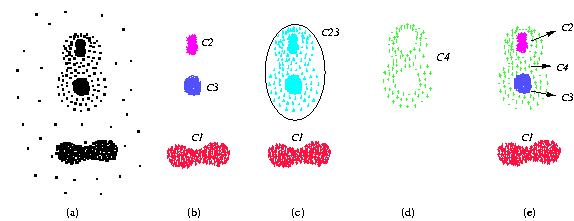
Most clustering algorithms report either
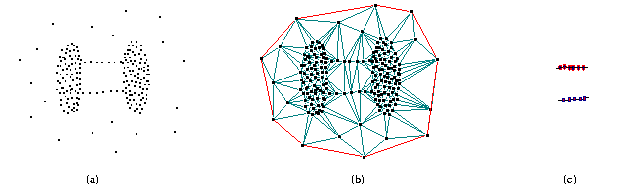
Clustering methods are inclined to report the big cluster (C23 in Figure 1(c)) as one cluster because the intra-cluster distance of cluster C4 (sparse cluster) is greater than the inter-cluster distance between the high-density clusters (C2 or C3) and the sparse cluster (C4). Apart from the three high-density clusters, the sparse cluster is also important for further correlation investigation between themes. Spotting and locating interesting groups in a particular theme is the starting point of exploratory data analysis. If we assume that points represent crime incidents around cities and surrounding suburbs, then mere density is unable to find correlation between crime incidents and suburbs by missing the distinction between the sparse cluster and the high-density clusters. Often, this phenomenon is found in real data, such as big cities having more crime incidents surrounded by suburbs recording relatively less. Moreover, detection of a boundary allows for exploration of a geographical feature that can explain the sharp decrease in density and frequency (the crimes reported are for an interval of time).
Hierarchical clustering with simple linkage corresponds to computing the Minimum Spanning Tree of the weighted graph. However, it is well-known that simple linkage suffers from bridges. Problems also arise for other strategies when clusters are connected only at bridges or chains. Well-known solutions for this find all bridges and cut-points [29]. This works when only one bridge connects two clusters.

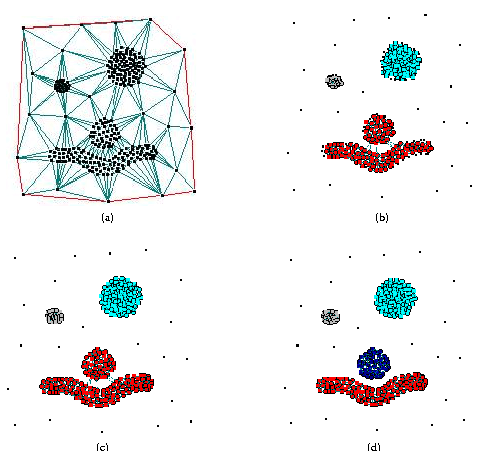
Consider the data in Figure 2(a). Figure 2(b) shows three clusters (C1, C2 and C3). Figure 2(c) shows that there are three path-like bridges connecting two clusters (C1 and C2) while one connecting two clusters (C2 and C3). There are no bridges or cut-points between clusters C1 and C2 while there are between clusters C2 and C3. Therefore, the approach using bridges and cut-points fails to detect two clusters linked by multiple bridges, thus generates two clusters C12 and C3 as shown in Figure 2(d).

Visual inspection of Figure 3(a) reveals four high-density clusters and one sparse cluster. Figure 3(b) highlights the four high-density clusters with labels C1 to C4 and one sparse cluster with label C5. However, using only global arguments is very difficult to obtain a reply from a clustering system that suggests these five clusters simultaneously. Settings of user-supplied arguments alternate between a reply that
This is similar to finding sharp gradient change, the boundaries of
clusters, in point density. Note that, we do not have a continuous density
but a discrete point set. The model that does not extrapolate or interpolate
is the discrete graph. One possibility is to use the complete graph, with
all edges weighed by the geographical distance. Here, the strength of interaction
between points is inversely proportional to the length of edge (recall
that distance decays effect [2]).
However, if we have n data points, there is no need to have a model
of size (n2). Moreover, clustering
is a summarisation operation and the goal is to obtain the discrete relation
pi is in the same cluster as pj for
all pi,pj
(n2). Moreover, clustering
is a summarisation operation and the goal is to obtain the discrete relation
pi is in the same cluster as pj for
all pi,pj P (a sub-relation of the complete graph). Thus, clustering is to
detect and remove inconsistent interactions (edges) in the graph modelling
proximity.
P (a sub-relation of the complete graph). Thus, clustering is to
detect and remove inconsistent interactions (edges) in the graph modelling
proximity.
We already mentioned that, despite that raster and vector representations are widely used in modelling geographical databases, they do not consistently capture spatial proximity for point-data sets [10,11]. The Voronoi diagram offers an alternative to overcome the drawbacks of conventional data models [10]. The Voronoi diagram uniquely captures spatial proximity and represents the topology explicitly with the dual graph known as the Delaunay Triangulation. Each Delaunay edge is an explicit representation of a neighbourhood relation between points.
Because Delaunay Triangulations are not unique when co-circularity occurs we use Delaunay Diagrams. These are the result of removing all edges e in the Delaunay Triangulations that are sides of a triangle whose vertices are co-circular with a fourth point. Even in the presence of co-circularity, Delaunay Diagrams guarantee a unique topology. They can be constructed effectively and efficiently (only O(n log n) time). The structure is succinct [21]; the number of edges is linear to the number of points and the expected number of edges incident to point is a constant value. In addition, the effect of long edges is minimised since the Delaunay Diagram is as equilateral as possible. Further, it is a hybrid approach of the two widely adopted models. It is geographically comprehensive like the raster model and holds explicit adjacency like the vector model.
More robust alternatives have been proposed along the paradigm of edge-removal from the Delaunay Triangulation to obtain the clusters. One alternative looks at the perimeter (sum of length of edges) of the triangles (or facets) of the Delaunay Diagram. The intuition is that, given the nature of Delaunay Diagrams (where a circumcircle of a Delaunay Triangle does not include any other data point), triangles with large perimeter must have vertices that are not in the same cluster. Estivill-Castro and Houle [6] successfully derive the number of clusters using an one-dimensional classification of perimeter values. Another approaches are Kang et al. [15] and Eldershaw and Hegland [4]. They analyse the length of Delaunay edges to find clusters of arbitrary shapes. The intuition is similar, and edges that are too long are classified as inter-cluster edges and removed. The relative success of these previous approaches demonstrates that Delaunay Triangulations contain much implicit proximity information.
However, these previous ideas use directly Delaunay Triangulations and return inconsistent results in the presence of co-circularity. More seriously, they use a global argument as a threshold to discriminate perimeter values or edges lengths. This kind of static approach is not able to detect local variations, and again, fails to identify clusters in situations like those illustrated in Section 2. Recently, Estivill-Castro and Lee [7] propose a dynamic approach which utilises both global and local variations. The idea behind this method is to find relatively high-density clusters or localised excesses based on Delaunay Diagram. This approach overcomes some problems of static approaches and produces localised multi-level clusters. But, it still fails to find relatively sparse clusters in situations like those in Section 2.1 and Section 2.3.
There are several measures for describing dispersion in statistical
spatial analysis. Undoubtedly, the standard deviation and its square, the
variance, are the most valuable and popular [27].
Thus, for the moment, we may say that AUTOCLUST detects points whose incident
edges exhibit lengths that have unusually large standard deviation. In
order to precisely define this notion we introduce the following notation.
In what follows, let P = {p1,p2,...,
pn} denote a set of n points in 2 dimensions and
let DD(P) denote the corresponding Delaunay Diagram of P.
The graph DD(P) is a planar map that contains vertices and
edges. Edges of DD(P) will be called Delaunay edges. For
a point pi P (a vertex
of DD(P)), the neighbourhood N(pi)
is the set of Delaunay edges incident to point
pi.
Definition 4.1.1 We denote by Local_Mean(pi) the mean length of edges in N(pi). That is,
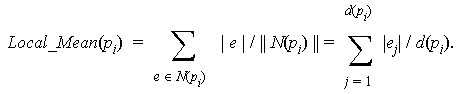
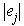 denotes to the length of Delaunay edge ej.
denotes to the length of Delaunay edge ej.
Definition 4.1.2 We denote by Local_St_Dev(pi) the standard deviation in the length of edges in N(pi). That is,
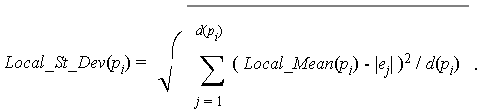
Thus, an edge ej incident to a point pi could potentially be labelled as inter-cluster (too long) if
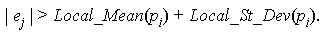
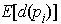 = 6 in Delaunay Diagrams.
Thus, we now introduce measures that incorporate global and local effects,
and in fact, this measure will result in tests that make a decision on
each edge using the data of all
= 6 in Delaunay Diagrams.
Thus, we now introduce measures that incorporate global and local effects,
and in fact, this measure will result in tests that make a decision on
each edge using the data of all 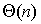 edges in
DD(P).
edges in
DD(P).
Definition 4.1.3We denote by Mean_St_Dev(P) the average of the Local_St_Dev(pi) values as we let pi be each point in P. That is,
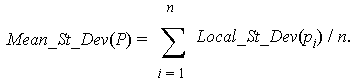
Note that, a value of edge-length spread like Local_St_Dev(pi) is large or small only in relation to the global value reflected in Mean_St_Dev(P). Thus, we introduce an indicator of the relative size of Local_St_Dev(pi) with respect to Mean_St_Dev(P).
Definition 4.1.4We let Relative_St_Dev(pi) denote the ratio of Local_St_Dev(pi) and Mean_St_Dev(P). That is,
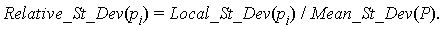
With this tool we propose to discriminate edges into those unusually short, those unusually long and those that seem to be proper intra-cluster edges.
Definition 4.1.5 An edge ej
N(pi) belongs to Short_Edges(pi) if and only if the
length of ej is less than
Local_Mean(pi) - Mean_St_Dev(P).
That is,
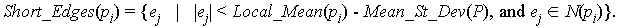
Definition 4.1.6 An edge ej
N(pi) belongs to
Long_Edges(pi) if and only if the
length of ej is greater than Local_Mean(pi) + Mean_St_Dev(P).
That is,
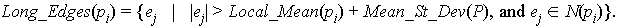
Definition 4.1.7 Other_Edges(pi) denotes the subset of N(pi) whose edges are greater than or equal to Local_Mean(pi) - Mean_St_Dev(P), and less than or equal to Local_Mean(pi) + Mean_St_Dev(P). That is,
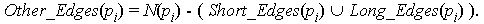
Note that, for each pi, the neighbourhood N(pi) is partitioned into exactly 3 subsets: Short_Edges(pi), Long_Edges(pi) and Other_Edges(pi). However, an edge linking pi with pj may belong, for example, to both Short_Edges(pi) and Other_Edges(pj).
Short_Edges(pi) eliminates some bridges,
while if such e happens inside a cluster, its removal can later
be recuperated using analysis of connected components. Later phases of
our algorithm handle other types of bridges and recuperate
Short_Edges
that are intra-cluster links.
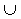 Short_Edges(pi) for some pi
P, we now give another justifications. Note that the analysis of
edges in DD(P) is the means towards grouping points, towards
clustering. We noted that the relation pi is in the same
cluster as pj is a subset of the complete graph and encodes
the clustering. This is what establishes the connection between grouping
points and the analysis of edges. Previous clustering algorithms using
Delaunay Triangulation [4,6,15]
focus much more on edges because all operations and cut-off criteria functions
are performed and formulated based on edge analysis. AUTOCLUST is closer
to the objective of grouping points because
Local_Mean(pi)
and Local_St_Dev(pi) report on local behaviour
around pi. These values represent behaviour of points
more than that of edges. Global effects are incorporated in discriminating
Long_Edges(pi), Short_Edges(pi)
and
Other_Edges(pi), with the use of Mean_St_Dev(P).
This makes all the n points influence the decisions for any other
pi. Perturbations of a point pj away
from a point pi do not affect the Delaunay Diagram in
the vicinity of pi. However, the relative configuration
of other points pj away from pi does
influence Mean_St_Dev(P).
Short_Edges(pi) for some
pi
P, first recall that border points pi of a cluster
C are expected to have Local_Mean(pi) and
Local_St_Dev(pi)
larger than points totally inside the cluster C. Thus, if Local_Mean(pi)
and
Local_St_Dev(pi) where statistically meaningful
in that were supported on a large sample, a statistical test to remove
unusually long edges would have the form
Short_Edges(pi) for some pi
P, we now give another justifications. Note that the analysis of
edges in DD(P) is the means towards grouping points, towards
clustering. We noted that the relation pi is in the same
cluster as pj is a subset of the complete graph and encodes
the clustering. This is what establishes the connection between grouping
points and the analysis of edges. Previous clustering algorithms using
Delaunay Triangulation [4,6,15]
focus much more on edges because all operations and cut-off criteria functions
are performed and formulated based on edge analysis. AUTOCLUST is closer
to the objective of grouping points because
Local_Mean(pi)
and Local_St_Dev(pi) report on local behaviour
around pi. These values represent behaviour of points
more than that of edges. Global effects are incorporated in discriminating
Long_Edges(pi), Short_Edges(pi)
and
Other_Edges(pi), with the use of Mean_St_Dev(P).
This makes all the n points influence the decisions for any other
pi. Perturbations of a point pj away
from a point pi do not affect the Delaunay Diagram in
the vicinity of pi. However, the relative configuration
of other points pj away from pi does
influence Mean_St_Dev(P).
Short_Edges(pi) for some
pi
P, first recall that border points pi of a cluster
C are expected to have Local_Mean(pi) and
Local_St_Dev(pi)
larger than points totally inside the cluster C. Thus, if Local_Mean(pi)
and
Local_St_Dev(pi) where statistically meaningful
in that were supported on a large sample, a statistical test to remove
unusually long edges would have the form
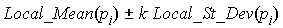
However, for a point pi inside a cluster C, there is uniformity around it, so all its incident edges have similar lengths and Local_St_Dev(pi) is relatively small. In this case, we would set the value of k to be larger than 1 in order to widen the acceptance interval and make sure we preserve edges inside a cluster. On the other hand, for a point pi that does not belong to any cluster (an outlier or noise), there are long edges around it to reach other points. This makes Local_Mean(pi) large and because of scale that Local_St_Dev(pi) is in the same units as Local_Mean(pi), Local_St_Dev(pi) is relatively large. Thus, in this case, we would set the value of k to be less than one in order to restrict more the acceptance interval and ensure we remove more edges incident to an outlier.
The inverse of Relative_St_Dev(pi) fulfils perfectly the role required for the factor k. It is less than one for those points pi that locally exhibit more spread (of length of their incident edges) than the generality of all points in P. It is larger than one for those points pi that locally exhibit less spread than the generality of all points in P. Incorporating k = Relative_St_Dev(pi)-1 into the statistical test, we have the following derivation.
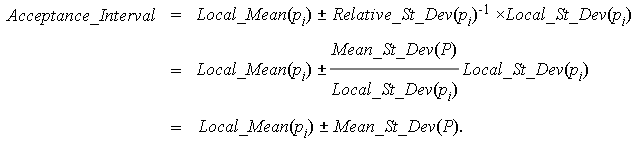
Observation 4.3.1Let pi
P be such that
Other_Edges(pi) 
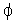 .
Then, all edges e Other_Edges(pi) connect
pi to the same non-trivial connected component.
.
Then, all edges e Other_Edges(pi) connect
pi to the same non-trivial connected component.
Using our notation, this means that if two edges ej = (pi,pj) and ek = (pi,pk) are in Other_Edges(pi), then CC[pj] = CC[pk]. The observation follows trivially from the fact that pj and pk are connected by the path ej,ek. Now, we recuperate Short_Edges, and in some cases, revise the connected component for pi. If all edges in Short_Edges(pi) suggest unanimously a connected component, pi is integrated to that suggestion. If there are two edges in Short_Edges(pi) suggesting different connected components, the largest is adopted. While Other_Edges(pi) participate in the creation of the connected components, now they delegate precedence to the suggestion by Short_Edges(pi) (which in the large majority of the cases is the same suggestion). The component swap typically occurs on isolated boundary points that have no Other_Edges (for example, the isolated points on the left of the bottom cluster in Figure 5(b)). Details of this process are as follows.
and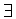 (e = (pi,pj))
Short_Edges(pi), CC[pj]
is a non-trivial connected component.
CC[pk], then
Short_Edges(pi), the size
(e = (pi,pj))
Short_Edges(pi), CC[pj]
is a non-trivial connected component.
CC[pk], then
Short_Edges(pi), the size 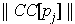 and let
and let 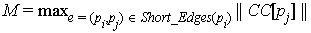 . Short_Edges(pi)
connect pi to. ShortEdges(pi)
that connect to C.
. Short_Edges(pi)
connect pi to. ShortEdges(pi)
that connect to C. (e = (pi,pj))
Short_Edges(pi), CC[pj]
is the same connected component C.
(e = (pi,pj))
Short_Edges(pi), CC[pj]
is the same connected component C. .
.
Definition 4.3.1 The k-neighbourhood Nk,G(pi) of a vertex pi in graph G is the set of edges of G that belong to a path of k or less edges starting at pi.
The third phase, now computes Local_Mean for 2-neighborhoods.
Definition 4.3.2 We denote by Local_Meank,G(pi) the mean length of edges in Nk,G(pi). That is,
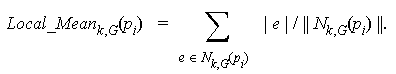
For each point pi, this phase simply removes all edges
in
N2,G(pi) that are long edges.
That is, all
e N2,G(pi)
such that  > Local_Mean2,G(pi)
+ Mean_St_Dev(P).
> Local_Mean2,G(pi)
+ Mean_St_Dev(P).
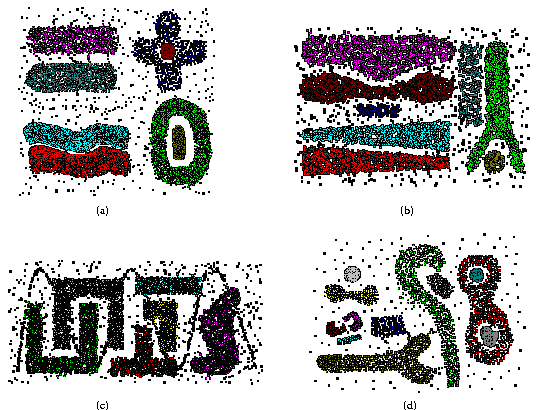
The data in Figure 6(a) is the result of synthetic data generation aimed at creating situations where clustering methods typically fail. Section 2 explains these types of situations. The clustering obtained with AUTOCLUST demonstrates its robustness. AUTOCLUST correctly identifies two clusters connected by multiple bridges in the top-left corner of Figure 6(a). AUTOCLUST has no difficulty in detecting a cross-shaped, but sparse cluster around a high-density cluster at the top-right corner of that data set. Again, this mimics real-world cases like densely populated city surrounded by slightly less dense suburbs. AUTOCLUST successfully reports the two high-density clusters separated by a twisting narrow gap (at the bottom-left of the data set). This mimics real-world situations where a river separates two highly populated areas. AUTOCLUST correctly reports the doughnut-shaped cluster and the surrounded island-shaped cluster (at the bottom-right of that data set).
The data sets in Figure 6(b) and Figure 6(c) belong to CHAMELEON's benchmark [16]. Regardless of the challenge posed by different sizes, different densities, and different separations (inter-cluster distances), AUTOCLUST correctly identifies 8 clusters and 6 clusters, respectively. Some of these clusters have very little space between them, but AUTOCLUST still detects these boundaries.
The data in Figure 6(d), consists of 12 clusters of various shapes and different densities. Note that many are not convex. AUTOCLUST successfully detects all of them.
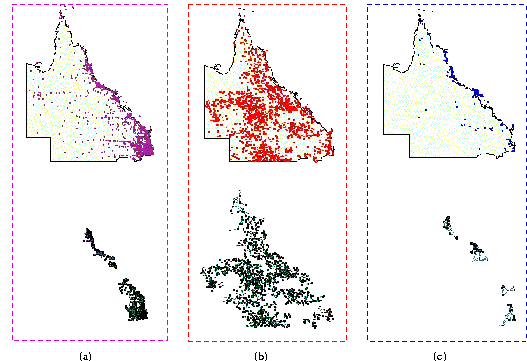
The data set displayed in Figure 7(b) represents landing grounds including aerodromes and airports. Visual inspection does not suggest any significant cluster. Landing grounds seem to be scattered all over Queensland. AUTOCLUST groups 90 percent of them into a large cluster that covers almost all Queensland. AUTOCLUST's results are consistent with the fact that there is no special pattern in landing grounds. AUTOCLUST also detects two small clusters in the southern portion of Brisbane. Note that, visual inspection reveals that there is less density for landing grounds surrounding the concentrated living areas near Brisbane. Creating the two other clusters South and East of Brisbane. Densely populated urban areas are not likely to have enough space for many airports. Conversely, sparsely populated in-land areas are likely to have enough space for small aerodromes.
Figure 7(c) illustrates a data set for national parks in Queensland. National parks are generally located along the coast and the Great Barrier Reef. AUTOCLUST successfully derives clusters directly overlying the major cities, urban areas and coastal areas. It finds two high-density clusters including more than half of national parks on the outer margin of Australia's continental shelf. Two less dense clusters are detected around urban areas.
We compare AUTOCLUST with AMOEBA [7].
AMOEBA also requires O(n log n) time and has been
shown to be very efficient, (small constant under the O notation).
We generated 7 types of data sets based on a simple mixture model. The
number of points varies from 1,000 to 100,000. Each data set has 10 randomly
distributed cluster centres within the unit square [0, 1] 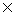 [0, 1] and 10 percent of the total number of points are just noise points
(selected at random within the unit square [0, 1]
[0, 1] ). Since AUTOCLUST and AMOEBA require spatial proximity modelling
(Delaunay Diagram), the run time comparison shown in Figure 8
includes the time for constructing their respective data structures. All
the experiments were performed on a 550MHz Pentium III workstation with
128MB memory.
[0, 1] and 10 percent of the total number of points are just noise points
(selected at random within the unit square [0, 1]
[0, 1] ). Since AUTOCLUST and AMOEBA require spatial proximity modelling
(Delaunay Diagram), the run time comparison shown in Figure 8
includes the time for constructing their respective data structures. All
the experiments were performed on a 550MHz Pentium III workstation with
128MB memory.
Figure 8 demonstrates that AUTOCLUST outperforms AMOEBA with respect to CPU-time by a small margin. Note that, however, the exploration time to find best-fit arguments for AMOEBA is not included. AUTOCLUST is argument free. Thus, in exploratory data analysis exercises AUTOCLUST will easily outperform the use of AMOEBA or other clustering methods that need parameter tuning. The experimental results shown in Figure 8 include the time requirements for I/O and clustering process. These experimental results illustrate that AUTOCLUST is efficient in terms of time complexity and scalable to large data sets.
We expect that our methods will extended in two directions. First, the
approach can be extended to 3 dimensions by computing a spanner graph of
linear size and obtaining local and global information efficiently [3]
from this graph. Second, the approach can naturally be extended to other
metrics with well-defined Delaunay Diagrams like Manhattan distance or 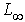 distances. Further research will explore these directions.
distances. Further research will explore these directions.