![]()
![]()
![]()
Robert L. Wilby
Division of Geography, University of Derby, Derby, DE22 1GB, UK
E-mail: R.L.Wilby@Derby.ac.uk
Colin Harpham and Martin R. Brown
Division of Computing, University of Derby, Derby, DE22 1GB, UK
E-mail: C.Harpham@Derby.ac.uk
E-mail: M.R.Brown@Derby.ac.uk
Elspeth Cranston and Edmund J. Darby
Loughborough Ecologists, 226 Charnwood Road, Shepshed, Leicestershire,
LE12 9NR, UK
E-mail: LboroughEcols@cs.com
In order to evaluate the influence of environmental factors it was necessary to build models using all the available data. However, although this is useful in terms of developing the most accurate model from those data and identifying key biological responses, there is no means of determining how accurate these models are at predicting species abundance in previously unseen situations. It is only by excluding data from a model's 'training' that one can determine how good that model is at generalising to unknown situations and avoid 'over fitting' the models to the training data.
Although the initial models provided the required results in the first instance it was felt that inductive learning models could provide an alternative, non-linear solution. For example, the statistical models that were developed assumed that the underlying relationship between each species and environmental factors was linear. This is not necessarily the most appropriate relationship in certain cases and alternative non-linear relationships were explored.
Although neural networks have only been used in a limited number of ecological studies in the past (for example, Recknagel et al. [1997] and Whitehead et al. [1997] investigated the use of neural networks for modelling algal blooms, and Lek et al. [1996] developed models linking trout spawning sites and habitat characteristics), they have been used more frequently in environmental and hydrological contexts (for example, Maier and Dandy, 2000; Dawson and Wilby 2000). They would appear to be well suited to problems of this nature due to their ability to handle non-linear, noisy, and inconsistent data.
This paper presents preliminary results from this work. Section 2 introduces inductive learning algorithms and discusses, in more detail, those used in this study. Section 3 discusses how the data were gathered and manipulated, Section 4 presents the results from this preliminary study and Section 5 presents conclusions and recommendations for future work.
In this paper the performance of three types of inductive learning algorithm are compared. First, the See5 algorithm, which assumes the unknown function can be represented by a decision tree. Second, by a multi layer perceptron (artificial neural network) which assumes that the unknown function can be represented by a multilayer, feed forward network of sigmoid units. Third, by a radial basis function network which models the unknown function using a network of Gaussian basis functions.
ANNs mimic the behaviour of their biological counterparts. They are represented by a number of neurons (c.f. brain cells) connected together in a network by a number of links (c.f. axons). By adjusting the strength, or weight, of the links between the neurons (c.f. synapses) one is able to 'train' an artificial neural network to behave in different ways.
From this simple representation, the neural network engineer is able to implement countless ANN types. For example, ANNs can be constructed in different ways by arranging the neurons into layers or groups. The links joining neurons can be configured to allow data to flow in different directions through a network. Different types of neurons can be used in a network that 'activate' in different ways, and different training algorithms can be employed in an attempt to 'optimise' a network's performance.
Although neural networks come in various forms, by far the most popular structure is the feed forward network architecture shown in Figure 1. In this configuration, numeric inputs to the network are passed forward from an input layer, through one or more hidden layers (one hidden layer is shown in Figure 1) to an output layer. As these data pass through a network they are modified according to 'weights' on each connecting link. At each neuron the value of its inputs are combined and an appropriate transfer function applied (for example, sigmoid, hyperbolic tangent, etc.). A neuron then produces an output response that is passed on to the next neuron it is linked to (or out of the network). Thus, for a given set of inputs to a neural network, a particular output response is produced. A network can be trained to respond in different ways to different inputs by adjusting the weights linking its neurons together - thus a functional mapping is produced from a set of predictors to a set of predictands.
This architecture represents both the multi layer perceptron (MLP) and
the radial basis function network (RBF) - the two neural network types
used within this study.
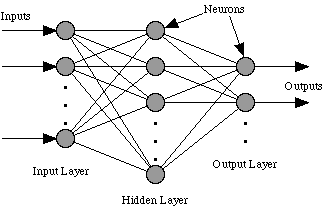
Figure 1 Feedforward ANN Architecture
Further detail of this training algorithm and the MLP are beyond the intended scope of this paper as they have been documented many times before. The interested reader is directed towards texts such as Gallant (1993) and Bishop (1995) for more details.
Training an RBF involves two stages. First, the basis functions must be established using an algorithm to cluster data in the training set. Typical ways to do this include Kohohen self organising maps (Kohohen, 1984; 1990), k-means clustering, decision trees (Kubat, 1998), genetic algorithms or orthogonal least squares and Max-Min algorithms (Song, 1996). In this study both K-means clustering and genetic algorithms (discussed below) have been used. K-means clustering involves sorting all objects into a predefined number of groups by minimising the total squared Euclidian distance for each object with respect to its nearest cluster centre.
Once the basis centres have been established it is necessary to fix the weights linking the hidden and the output layers. If neurons in the output layer contain linear activation functions, these weights can be calculated directly using matrix inversion (using singular value decomposition) and matrix multiplication (as used in this study). Alternatively, if a non-linear activation function is used, the weights can be established using an iterative algorithm such as error backpropogation.
Because of the direct calculation of weights in an RBF it is usually much quicker to train than an equivalent MLP. However, in some cases accuracy is compromised and an RBF can be less able to generalise so trade-offs must be made. For more information on the radial basis function the interested reader is directed towards texts such as Schalkoff (1997) and Orr (1996).
The GA has a population of individuals competing against one another in relation to a measure of fitness. At each stage of the process some individuals will breed, others will die off, and new individuals will arise through combination and mutation. In its simplest form the GA utilises fixed length character strings and steps through the following algorithm (Goldberg, 1989):
| 1 | Randomly create an initial population of individual character strings (for example, this can be achieved by generating a binary string using computer simulated successive tosses of an unbiased coin). |
|
|
Assign a 'fitness' value to each individual in the population using a chosen measure (for example, mean squared error). |
|
|
Create a new population by applying reproduction, crossover and mutation operations to the individual strings. These operations are applied to chosen population strings with a probability based on each string's fitness. Reproduction simply involves copying an existing individual into the new population. Crossover involves swapping characters between two strings from a randomly chosen starting point in those strings. Mutation involves creating a new string from an existing one by randomly mutating a character. |
|
|
Evaluate the fitness of the new population. |
|
|
If the convergence criteria has not been reached go to step 3. |
Following a fixed number of generations the string with the best overall fitness value is chosen. Convergence is not achieved in the usual sense since there is always an element of mutation which reintroduces an individual string to the search space.
Studies of GAs for function optimisation (De Jong, 1975) have indicated that good performance requires a high probability of crossover, a low probability of mutation and a moderate population size. Generally, the probability of crossover is set between 0.4 and 0.9 and for the purpose of these experiments a value of 0.7 was used. For the probability of mutation (Pmutation) the empirically derived formula (Schaffer et al., 1989) was used:
![]()
in which L is the string length (varying from 1440 for an RBF with 15 centres to 3840 for an RBF with 40 centres) and N the population size (50 in this case). The maximum number of generations was set at 200 since initial tests showed no improvement using a greater number.
In this application the GA is utilised to evolve an optimal set of basis centres for the RBF network. Singular value decomposition is still used to calculate the second layer weights and the fitness value is the MSE of the training set.
In these experiments the See5 inductive learning decision tree algorithm was used. This is a revised version of C4.5 and ID3 (Quinlan 1986, 1993) and includes a number of additional options for implementation. For example, the Boosting option causes a number of classifiers to be constructed - when a case is classified, all of these classifiers are consulted before a decision is made. Boosting will often give a higher predictive accuracy at the expense of increased classifier construction time. For these experiments however, data set boosting was not found to give any improvement in prediction accuracy.
In applications with differential misclassification costs, it is sometimes desirable to see what affect costs have on the construction of the classifier. In this case all misclassification costs were the same so this option was not implemented.
The macrophyte data set uses continuous attributes. When a continuous attribute is tested in a decision tree, there are branches corresponding to the conditions:
attribute value <= threshold and attribute value > threshold
for some threshold chosen by See5.
As a result, small movements in the attribute value near the threshold can change the branch taken from the test. There have been many methods proposed to deal with continuous attributes (Quinlan, 1988; Chan et al., 1992; Ching et al., 1995). An option available in See5 uses fuzzy thresholds to soften this knife-edge behaviour for decision trees by constructing an interval close to the threshold. Within this interval, both branches of the tree are explored and the results combined to give a predicted class.
Decision trees constructed by See5 are post pruned before they are presented to the user. The Pruning Certainty Factor governs the extent of this simplification. A higher value produces more elaborate decision trees and rule sets, while a lower value causes more extensive simplification. For this experiment a certainty factor of 25% was used.
Between 1991 and 1998 a number of macrophyte surveys were made by the Loughborough Ecologists in the Rivers Test and Itchen. Two different survey types were undertaken - two single downstream longitudinal surveys in 1991 and 1998 (covering reaches of up to 100m) and periodic, temporal surveys (covering reaches of approximately 20m). To assess macrophyte growth with respect to hydrological, meteorological and biological factors those data gathered from the temporal surveys are discussed here.
3.2 Parameter set
The temporal surveys involved establishing six base reference sites on the River Test and three sites on the River Itchen. Each site was visited approximately twenty five times over the seven year period - not necessarily at the same time(s) each year and not necessarily at equal time intervals. During these visits data were gathered on the presence of a number of macrophyte species - Ranunculus, Berula, Callitriche, Zannichellia, Hippuris, and Schoenoplectus. Presence of each species was recorded using a 0 to 8 scale from observations taken in each square metre at each reference site (see Table 2).
Previous research has assumed that the growth of Ranunculus in chalk streams relies on a function of several meteorological, hydrological and physiochemical processes (Wilby et al., 1998). Therefore, in parallel with the survey visits, data were obtained from the Environment Agency (Southern Region) from gauging stations close to the reference sites. These data included water quality data (for example, pH, conductivity, nitrates, phosphate levels, etc.) and hydrological data (daily cumecs). Meteorological data were also obtained from the Weather journal weather logs covering the same period and included factors such as rainfall, sunshine, air temperature etc. In total, 47 parameters were gathered. In order to reduce the complexities of the models developed, and to ease the analyses, it was felt that this parameter set should be reduced in some way. With this in mind a principal components analysis was undertaken to distil the parameters while still retaining as much information from the data as possible.
Before extracting the principle components from the data they were first split into five categories; hydrological, pulse, meteorological, water quality, and precursor water quality (this is a similar categorisation to that used by Wilby et al. [1998]). Hydrological factors included data such as monthly mean flow, three, six, nine and twelve month moving averages of flow. Pulse factors included measures of the number of days in a month that one day's flow exceeded the previous day's flow by +5% and +10%. Meteorological data included monthly mean air temperature, maximum and minimum air temperature, hours of sunshine, etc. Water quality data were recorded both for the current month and the precursor month. Table 1 presents a summary of the total number of parameters in each category and how, through the principal components analysis, these data were reduced from 47 parameters to 13 key factors. Table 1 also shows the percentage of variance explained by the new factors. In this case only 14% of the variance has been discarded when reducing the number of parameters by approximately 72%.
Three additional factors (that could not be comfortable categorised
as per Table 1) were included in the development of the inductive learning
models - monthly rainfall total (mm), month number (1-12) and site identification
number (1 to 9). This led to a total of 16 predictors available for developing
inductive learning models of Ranunculus.
|
|
|
|
|
| Hydrological |
|
|
|
| Pulse |
|
|
|
| Meteorological |
|
|
|
| Water Quality |
|
|
|
| Precursor Water Quality |
|
|
|
| Total |
|
|
|
Table 1 Parameter classifications used in principal components analysis
3.3 Ranunculus abundance
During the surveys of the Rivers Test and Itchen, Ranunculus spp. was
classified using a non-linear, 0 to 8 cover category scale at each of the
reference sites. Each category represented the percentage cover of Ranunculus
as shown in Table 2 below:
| Cover Category |
|
|
|
| 0 |
|
|
|
| 1 |
|
|
|
| 2 |
|
|
|
| 3 |
|
|
|
| 4 |
|
|
|
| 5 |
|
|
|
| 6 |
|
|
|
| 7 |
|
|
|
| 8 |
|
|
|
Table 2 Classification of Ranunculus percentage cover categories
Although categories are the de facto means of representation for See5 and discriminant analyses techniques, there are different ways that categories can be represented as outputs from feed forward neural networks. Three techniques were therefore explored to represent the cover category of Ranunculus spp in the ANN models. In the first instance the categories 0 - 8 were used as they stood, generated from a single network output. In this case 0 would be represented by output values less than 0.5, cover category 1 by values 0.5 to 1.5, 2 by 1.5 to 2.5, and so on. However, because these categories represent an underlying non-linear scale, it was felt that better results might be obtained by using the mean percentage cover of each category. For example, category 1 was represented by 0.05%, category 2 by 0.55%, category 3 by 3% and so on - see Table 2.
Better results, however, came from a third alternative - the use of a thermometer scale after that used by Gallant (1993). In this case the neural network has eight output nodes, each of which is trained to produce an output of approximately 0 (values less than 0.2) or approximately 1 (values greater than 0.8). The thermometer scaling shown in Table 2 identifies how each of the cover categories is represented by the output from all eight neurons. For example, cover category 3 would be represented by outputs of one (values greater than 0.8) from nodes 1,2,3 and zeros (values less than 0.2) from the remaining five nodes (nodes 4,5,6,7,8). In this way changes from one cover category to the next are represented by a change in only one node's output. In the example given so far, by changing the output from node 4 from zero to one, the network would represent a cover category of 4 (as 00001111). Thus, a network is able to map slight changes in inputs to only minor changes in the output for each change in cover category. For binary and unitary scales this would not be the case.
| Model | Correct Classifications | % of Total | No. of Parameters |
| SWMLR | 128 | 60.95 | 8 |
| MLP | 152 | 72.38 | 133 |
| RBF (KM) | 146 | 69.52 | 3600 |
| RBF (GA) | 148 | 70.48 | 255 |
| See5 | 137 | 65.23 | 43 |
Table 3 Classification results of all models
The MLP was trained with 5,10, and 20 hidden nodes for 200, 400, 600, 800, 1000, 1500, 2000 epochs. The momentum rate set to 0.9, training rate to 0.1. The results presented are from a network trained for 400 epochs with 5 hidden nodes.
For RBFs trained using KMeans clustering (RBF (KM)), the best result was obtained from a network containing 150 basis centres (i.e. 150 hidden nodes). RBF networks with 5, 10, 20, 50, and 100 basis centres were also developed and tested. When GA training was used the best results were produced by a network containing 15 basis centres.
For comparative purposes a number of other tests were also undertaken. First, in order to assess the ability of the techniques to model the underlying function and compare results with earlier linear models, all the data were used for training and testing. In this case it was very easy to develop a model that could correctly classify all 210 data points. For example, an RBF was constructed within minutes that could correctly classify all the data. This emphasises the accuracy one can achieve by using non-linear techniques on data sets such as these.
In order to assess the impact of precursor macrophyte abundance, additional models were also produced containing these parameters as predictors. In this case model accuracy could be improved by over 10%. For example, an RBF with 50 basis centres was able to correctly classify 172 (81.9%) observations. However, although precursor observations could be included in the models it was felt that a more rigorous test would involve excluding these parameters. If Ranunculus abundance at particular reference sites was relatively stable, the models developed would focus on this predictor at the detriment of identifying influential factors on Ranunculus growth.
Another test involved using all 47 parameters to develop the models rather than the reduced parameter set obtained following principal components analysis. Using all 47 parameters led to poorer models than those presented here. For example, the best results obtained from an RBF with all 47 predictors was 142 (68%) correct classifications. This shows that any potential loss in information from the reduced data set is compensated by the simplification of the resultant models.
In Table 3 the number of parameters in each model has been presented giving an indication of their parsimony. For the SWMLR model the number of parameters is based on the average number of parameters used for all 15 models produced. The MLP and RBF models are calculated according to the number of links and, where appropriate, node biases in each network. The number of parameters in See5 is calculated using the mean number of leaf nodes on the decision trees for the 15 folds. This gives the number of conjunctions that are used for making decisions. This approach for comparing the complexity of decision trees with that used by neural networks was used by Dietterich et al. (1995). However, their comparison used decision tree leaf nodes and neural network hidden nodes.
As can be seen, the SWMLR is the most parsimonious model even though its accuracy is around 10% lower than that of other models (and See5 is not too far behind). The RBF(KM) model is particularly complex - the result of selecting a network containing 150 basis centres. It is worth noting that similar results were obtained with an RBF network with only 20 nodes (143 correct classifications) - in which case the model contained 'only' 480 parameters.
1) Although less accurate in terms of predictive abilities, the SWMLR and See5 models are much more parsimonious in terms of parameter usage.
2) If one wishes to identify those factors that have most influence on species abundance, SWMLR and See5 are appropriate models to choose. The SWMLR procedure clearly identifies those parameters as weighted factors in the final model. However, one must remember that SWMLR identifies the strongest combined linear relationship and care must be taken not to overlook excluded factors from the stepwise procedure. See5 identifies significant factors in terms of those with the most entropy i.e. those which are the best discriminators. In contrast, due to the black-box nature of the neural network models, it is not easy to identify significant predictors of species growth from them.
3) In terms of development time, the MLP takes much longer to train than equivalent RBF, SWMLR and See5 models.
In conclusion, the purpose of the model will influence its choice. If one is interested in exploring those factors most influencing species abundance, See5 is the most appropriate of the inductive learning algorithms presented. If one requires an accurate model quickly, an RBF is most suitable. If one needs the most accurate model available then an MLP is shown to be the most appropriate in this case.
Cestnik, B. Konenenko, I. Bratko, I. 1987. ASSISTANT 86: A Knowledge Elicitation Tool for Sophisticated Users, in Bratko, I. and Navrac, N. (eds), Progress in Machine Learning, Sigma Press, UK.
Chan, K.C.C. Ching, J.Y. and Wong, A.K.C. 1992. A Probabilistic Inductive Learning Approach to the Acquisition of Knowledge in Medical Expert Systems. Proc. 5th IEEE Computer Based Medical Systems Symp. Durham NC.
Ching, J.Y. Wong, A.K.C. and Chan, C.C. 1995. Class Dependent Discretisation for Inductive Learning from Continuous and Mixed-mode Data. IEEE Trans. PAMI, 17(7) 641 - 645.
Dai, H. and MacBeth, C. 1997. Effects of learning parameters on learning procedure and performance of a BPNN, Neural Networks, 10, 1505 - 1521.
Dawson, C.W. 1996. A Neural Network Approach to Software Project Effort Estimation, Applications of Artificial Intelligence in Engineering, 1, 229 - 237.
Dawson, C.W. and Wilby, R. 1999. A comparison of artificial neural networks used for river flow forecasting, Hydrology and Earth System Sciences, 3(4), 529 - 540.
Dawson, C.W. and Wilby, R.L. 2000. Hydrological modelling using artificial neural networks', Progress in Physical Geography, in press.
De Jong, K.A. 1975. An analysis of the behaviour of a class of genetic adaptive systems. PhD dissertation, University of Michigan. Dissertational Abstracts International Vol 36(10), 5140B.
Dietterich, T.G. Hild, H. and Bakiri, G. 1995. A Comparison of ID3 and Back Propogation for English Text to Speech Mapping. Machine Learning,18, 51 - 80
Gallant, S.I. 1993. Neural Network Learning and Expert System, MIT Press, London
Goldberg, D.E. 1989. Genetic Algorithms in Search, Optimization and Machine Learning. Reading (MA), Addison-Wesley.
Holland, J. 1975. Adaptation in Natural and Artificial Systems. Ann Arbor: University of Michigan Press.
Jayawardena, A.W. Fernando, D.A.K. and Zhou, M.C. 1997. Comparison of Multilayer Perceptron and Radial Basis Function networks as tools for flood forecasting, Destructive Water: Water-Caused Natural Disaster, their Abatement and Control (Proceedings of the Conference at Anaheim, CA, June), IAHS Publication Number 239, 173 - 181.
Jayawardena, A.W. and Fernando, D.A.K. 1998. Use of Radial Basis Function Type Artificial Neural Networks for Runoff simulation, Computer-aided Civil and Infrastructure Engineering, 13(2), 91 - 99.
Kohohen, T. 1984. Self-organization and associative memory, Springer-Verlag, New York.
Kohohen, T. 1990. The self-organizing map, Proceedings of the IEEE, 78(9), 1464 - 1480.
Kubat, M. 1998. Decision tress can initialize radial-basis function networks, IEEE Transactions on Neural Networks, 9(5), 813 - 821.
Lek, S. Delacoste, M. Baran, P. Dimopoulos, I. Lauga, J. and Aulagnier, S. 1996. Application of neural networks to modelling nonlinear relationships in ecology. Ecological Modelling, 90(1), 39 - 52.
Magoulas, G.D. Vrahatis, M.N. and Androulakis, G.S. 1997. Effective backpropagation training with variable stepsize, Neural Networks, 10, 69 - 82.
Maier H.R. and Dandy G.C. 2000. Neural networks for the prediction and forecasting of water resources variables: a review of modelling issues and applications, Environmental Modelling and Software, 15(1), 101 - 123.
Mason, J.C. Tem'me, A. and Price, R.K. 1996. A Neural Network Model of Rainfall-Runoff Using Radial Basis Functions, Journal of Hydraulic Research, 34(4), 537 - 548.
Orr, M.J.L. 1996. Introduction to Radial Basis Function Networks, Centre for Cognitive Science, University of Edinburgh.
Quinlan, J.R. 1986. Induction of Decision Trees. Machine Learning, 1, 81 - 106.
Quinlan, J.R. 1988. Decision Trees and Multi-valued Attributes. In Hayes, J.E. Michie, D. and Richards, J. (eds), Machine Intelligence 11. Oxford University Press.
Quinlan, J.R. 1993. C4.5 Programs for machine learning. San Mateo CA: Morgan Kauffmann.
Recknagel, F. French, M. Harkonen, P. and Yabunaka, K. 1997. Artificial neural network approach for modelling and prediction of algal blooms, Ecological Modelling, 96, 11 - 28.
Rumelhart, D.E. and McClelland, J.L. (eds). 1986. Parallel Distributed Processing: Explorations in the Microstructures of Cognition, 1, MIT Press, Cambridge.
Schaffer, J.D., Caruana,, R.A., Eshelman, L.J. and Das, R. 1989. A study of control parameters affecting online performance of genetic algorithms for function optimisation. In Schaffer, J.D. (ed) Proceedings of the 11th International Joint Conference on Artificial Intelligence. Morgan Kaufmann, San Mateo.
Schalkoff, R.J. 1997. Artificial Neural Networks, McGraw-Hill.
Song, X.M. 1996. Radial Basis Function Networks for Empirical Modeling of Chemical Process, MSc Thesis, University of Helsinki, http://www.cs.Helsinki.FI/~xianming (28 January 1999).
Whitehead, P.G. Howard, A. and Arulmani, C. 1997. Modelling algal growth and transport in rivers: a comparison of time series analysis, dynamic mass balance and neural network techniques, Hydrobiologia, 349, 39 - 47.
Wilby, R.L. Cranston, L.E. and Darby, E.J. 1998. Factors governing macrophyte status in Hampshire chalk streams: implication for catchment management, Journal of the Chartered Institute of Water and Environmental Management, 12, 179 - 187.