![]()
![]()
![]()
The Genetic Algorithm is tested against the traditional K-Means method, and an unsupervised neural network (Kohonen's self organising map). First, through the use of artificial generated data a particular environment is set up, then a real world example, involving the electoral results in Portugal, is used. Another important aspect is related with the possibility of using GA in geographical clustering problems. It seems obvious that the flexibility offered by GA should encourage researchers to develop new and improve ways of tackle the clustering tasks in Geography.
Cluster analysis can be defined as "a wide variety of procedures that can be used to create a classification. These procedures empirically form "clusters" or groups of highly similar entities." (Aldenderfer, M., Blashfield, R. - 1984). In other words it can be said that cluster analysis defines groups of cases, through a number of procedures, which are more similar between them than all the others.
Largely used, cluster analysis has merited the attention of a very large number of academic disciplines. From marketing to geography they have been widely used and tested. Urban researchers are among those who have heavily relied on cluster algorithms within their research work (Openshaw and Wymer 1994, Plane and Rogerson 1994, Painho, Vasconcelos, Fonseca and Geirinhas 1997). Most of the work done on internal spatial and social structure of cities has in some way used classification as a basis for analysis.
Census data is surely the most fundamental source of information in urban research. Identification of deprivation areas, geodemographics and social services provision, are among the processes in urban research that rely on the use of census variables and classification techniques. It seems obvious that any improvement in classification methods is bound to have impacts in this area. This is especially important if we consider the specific problems usually associated with census data (Openshaw and Wymer 1994).
Before advancing in proposing new and improved ways of dealing with clustering tasks in geographic information systems environment one should consider the alternatives in terms of classifiers. This is especially important if one takes into account that flexibility is one of the major issues that can ease the work on adapting these classifiers to incorporate geographic aspects.
This paper starts with the discussion of some relevant aspects on clustering and geographic issues. After that the clustering methods used are briefly described, followed by the presentation of the empirical setting and its results, finally some conclusions are presented.
Another questionable aspect of these classifications is related with the quality issue. Partly, this issue can be addressed on the grounds that, it is better to have Geodemographics, in spite of the limitations, than nothing at all. This seems to be a reasonable argument, specially, if privacy issues come as a limitation in developing other approaches. Nevertheless it should not be used to prevent improvement on the existing methodologies.
It is also interesting to note the persistence of a number of geographers in criticise all the work in Geodemographics. It is obvious that a number of commercial interests have promised what they cannot deliver. It is also obvious that the academic community should not endorse these unreal expectations. But why concentrate on destroying what can be a very good opportunity to develop new fields of expertise and keep Geography in touch with the real world? It seems much more useful to propose improvements or new methodologies, and contribute to the development of new promising fields in Geography.
The performance of the classification methods in itself is not enough to solve all the problems related with the quality of census based classifications, but it is definitely an important issue. Openshaw, Blake and Wymer (1995) argue "in general, the quality of any area-based census classification reflects three major factors. First, the classification algorithm that is used, second, the way and extent to which knowledge about socio-spatial structure is used and is represented in the classification, and third, the sensitivity of the technology to what can be condensed to be the geographical realities of the spatial census data classification problem".
For some time now work has been done on the use of unsupervised neural networks, especially Kohonen Self-Organizing Map, in clustering procedures. A more flexible approach seems to be the main promise, this is particularly relevant when classifying census data (Openshaw and Wymer 1994) and also if the introduction of some kind of geographical knowledge is considered.
On the other hand one can approach the optimisation problem posed by clustering using Genetic Algorithms (GA) as the optimisation tool. GA have long been used in different kinds of complex problems, usually with encouraging results. In this paper a genetic algorithm is used to optimise the objective function used in the k-means algorithm. This measure of within cluster variance is used as a fitness function.
In spite of the value that new and improved classifiers can add to clustering tasks in Geography, probably the quantum leap that Openshaw and Wymer (1994) talk about will come not from the improvement of classifiers but from the introduction of some spatial reasoning in the process as they propose. Nevertheless the classifier used is of major significance, if not because of the performance then because it will condition the way in which geographical knowledge will be introduced in the clustering process.
Here the main objective of the work is to evaluate the GA approach to the clustering problem. It is well known that data quality is usually worst than what it should be and this problem is even more difficult to deal with when it comes to multidimensional data, which varies in precision and resolution. Clustering methods should be capable of providing satisfactory classifications and tackle the challenges prompted by the presence of some fuzziness in data. That's what the GA should be able to do, preferably better than the traditional methods like k-means. Having established this, one can think of other ways of using GA in cluster analysis, which are more adequate to treat spatial data and easy to couple with GIS.
The central idea in k-means is to start with an initial partition and then from there, by changing cluster membership, improve the partition. As Anderberg (1973) notes "The broad concept for this methods (non-hierarchical clustering methods) is very similar to that underlying the steepest descendent algorithms used for unconstrained optimisation in nonlinear programming".
Typically the k-means algorithm starts with an initialisation process in which seeds positions are defined. This initial step can have a significant impact on the performance of the method (Bradley and Fayyad, 1998) and can be done in a number of ways (Anderber,g 1973, Bradley and Fayyad, 1998). After the initial seed had been defined each data element is assigned to the nearest seed. The next step consists on repositioning the seeds, this can be done after all elements are assign to the nearest seed or as each one of the elements is assigned. After this, a new assignment step is necessary and process will go on until no further improvement can be made, in other words a local optimum has been found. Considering that the assignments will be done on the basis of the distance to the nearest seed, implicitly this process will produce a minimization of the "sum of the L2 distance squared between each data point and its nearest cluster center" (Bradley and Fayyad, 1998).
In the self-organization process the input vectors are presented to the network, and the cluster unit whose weight vector is closest (usually in terms of Euclidean distance) is chosen as the winner. The next step is to update the value of the winning unit and neighbouring units, this will approximate the values of the units to the one of the input vector. This can be viewed as a motion of the units in the direction of the input vector, the magnitude of this movement depends on the learning rate, which decreases along the process in order to obtain convergence.
Bearing in mind that Vector Quantization (VQ) is essentially the same as the k-means algorithm, and that the VQ is a special case of the SOM, in which the neighbourhood size is zero, one can say that there is a close relation between SOM and k-means. Openshaw and Wymer (1994) go further and say that the basic SOM algorithm " is essentially the same as a K means classifier; with a few differences due to neighbouring training which might well be regarded as a form of simulated annealing and it may provide better results and avoid some local optima."
In spite of the large number of applications of GA in different types of optimisation problems, there is very little research on using this kind of approach to the clustering problem. In fact, and bearing in mind the quality of the solutions that this technology has showed in different types of fields and problems (Beasley, Bull and Martin, 1993a, Mitchell, 1996) it makes perfect sense to try to use it in clustering problems.
The flexibility associated with GA is one important aspect to bear in mind. With the same genome representation and just by changing the fitness function one can have a different algorithm. In the case of spatial analysis this is particularly important since one can try different fitness functions in an exploratory phase.
The GA minimizes the square error of the cluster dispersion:
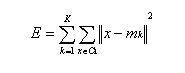
K being the number of clusters, mk the centre of cluster Ck, which makes it similar to the k-means algorithm.
In the genome each gene represents a data point and defines cluster membership. All necessary evolution operators can be implemented with this scheme. As pointed by Demiriz et all (1999) the major problem associated with this representation scheme is that it is not scalable, on the other hand it seems to be computationally efficient when the number of data points is not too large. The GA was implemented through the customisation of Galib (1996). The population size used was 100, with a replacement percentage of 50%, a crossover probability of 0,9 and a mutation probability of 0,01, uniform crossover was applied and 15000 generations were evaluated.
The data generated has the following characteristics: 750 observations, 16 variables, which make up 5 clusters.
After defining the centroid for each variable in the 5 clusters the program generated 150 elements around their class centroid, based on an error parameter, which is the "size" of the standard deviation of the error (which is normally distributed), on a 7-point scale. The term error is actually more a noise parameter, which is introduced in each element. This parameter really just increases and decreases the "tightness" of the clusters.
The real data are from the 1995 legislative elections in Portugal and is constituted by the voting percentages of the 5 major Portuguese parties, as well as abstention. The objective is to give an image of the behaviour of the different regions in terms of their voting patterns.
In the next step the error parameter was increased to 1.5. The "tightness" of the clusters was thus decreased, generating a greater number of outliers, shortening the distance between clusters. The classification is more challenging, due to difficulties that arise from "less clear" cluster boundaries. In this case K-means method performed rather poorly. In the clustering produced by the GA only 18 elements are misclassified. The original clusters are very clearly reconstructed and it is possible to detect the "interaction" between elements of the 301-450 class and 601-750 class, which deeply affected the K-Means method. The clustering made by the SOM produced the best results, although it's difficult to draw important conclusions on the superiority of SOM over the GA, due to the proximity in terms of results. Only 13 elements are misclassified (minus 5 when compared with the GA), and it is still possible to detect the "interaction" between elements of the 301-450 class and 601-750 class. Structurally there seems to be no important differences between the two approaches.
Finally the error parameter was increased to 2. The results are very clear, supporting the idea that GA and SOM will fail more as the error parameter increases but the fundamental structure of the data is still respected. Another important aspect is that the SOM and the GA have better performance in terms of optimising the "within cluster variability".
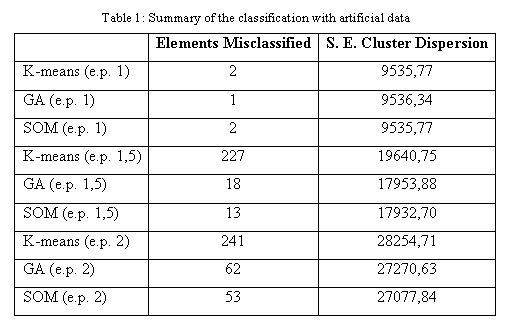
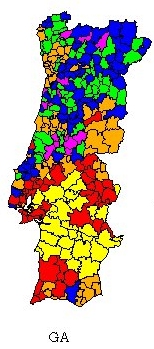
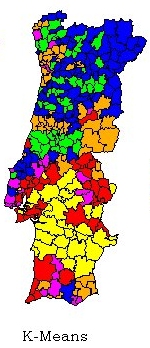
In general terms one can say that there are no major differences between them. Table 2 presents the values of the square error of the cluster dispersion:
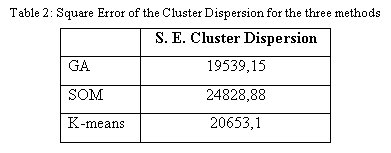
In this case the GA obtained the lowest value, which means that it was the best method in reducing the cluster dispersion, indicating a good performance in terms of optimisation.
It's important to note that this was not a completely fair trial because in the case of the K-Means and the Self Organising Map a commercial software with very sophisticated algorithms was used, whereas the Genetic Algorithm was implemented by an algorithm still under initial development that surely can be improved.
The future chanlenge consists on using different representation schemes for the GA and compare the qualities and shortcomings of the different representations. But the major challenge will be to use GA as the optimisation method and devising new and more spatial relevant objective functions that can be used in order to develop geographic clustering methods.
However it is too early to draw conclusions on which one is the best method, further and extensive testing would have to be done. It is known that the initialisation process can have major impacts on the k-means performance. Probably with a different and more sophisticated initialisation procedure the k-means results would be better. Nevertheless, a commercial statistical package was used, and the results should be enough to warn users of the problems that can happen when using the standard k-means algorithms.
Aldenderfer, M., Blashfield, R. 1984. Cluster analysis, Series: Quantitative Applications in the Social Sciences, Sage Publications
Anderberg, M. R. 1973. Cluster Analysis for Applications, Academic Press
Beasley, D., Bull, D.R., & Martin, R.R. 1993a. "An Overview of Genetic Algortihms: Part 1, Fundamentals", University Computing, 15(2) 58-69. Available by ftp from ENCORE (See Q15.3) in file: GA/papers/over93.ps.gz or from ftp://ralph.cs.cf.ac.uk/pub/papers/GAs/ga_overview1.ps
Beasley, D., Bull, D.R., & Martin, R.R. 1993b. "An Overview of Genetic Algortihms: Part 2, Research Topics", University Computing, 15(4) 170-181. Available by ftp from ENCORE (See Q15.3) in file: GA/papers/over93-2.ps.gz or from ftp://ralph.cs.cf.ac.uk/pub/papers/GAs/ga_overview2.ps
Bishop, C. M. 1995. Neural Networks for Pattern Recognition. Oxford University Press
Bradley, P. S., Fayyad, U. M. 1998. Refining Initial Points for K-Means Clustering, In J. Shavlik, editor, Proceedings of the Fifteenth International Conference on Machine Learning, Morgan Kaufmann, San Francisco
Churchill, G. 1995. Marketing Research: Methodological Foundations, 6th edition. Fort Worth, Texas: Dryden
Demiriz, A, Bennett, K. P., Embrechts, M. J. 1999. Semi-Supervised Clustering using Genetic Algorithms. Proceedings of Artificial Neural Networks in Engineering
Fausett, L 1994. Fundamentals of Neural Networks: Architectures, Algorithms, and Applications, Englewood Cliffs, NJ: Prentice Hall,
Fischer, M., & Gopal, S. 1993. Neurocomputing and Spatial Information Processing From General Considerations to a Low Dimensional Real World Application. In M. Painho (Ed.), Proceedings of the workshop on New Tools for Spatial Analysis (pp. 55-68). Lisboa: Eurostat.
Goldberg, D. 1989. Genetic Algorithms in Search, Optimization, and Machine Learning. Reading (MA): Addison-Wesley.
Gopal S. 1998. Artificial Neural Networks for Spatial Data Analysis, NCGIA Core Curriculum in GIScience, http://www.ncgia.ucsb.edu/giscc/units/u188/u188.html
Hartigan, J. 1975. Clustering Algorithms, Wiley Series in Probability and Mathematical Statistics, John Wiley & Sons.
Kohonen, T. 1988. Self-organization and Associative Memory (2nd Edition). Springer-Verlag: New York
Mitchell, M. 1996. An Introduction to Genetic Algorithms. MIT Press, Cambridge, Mass.
Openshaw S., & Openshaw C. 1997. Artificial Intelligence in Geography, Chichester, England, John Wiley & Sons
Openshaw, S., Blake, M., & Wymer, C. 1995. Using neurocomputing methods to classify Britain's residential areas. In Peter Fisher, Innovations in GIS 2 (pp. 97-111). Taylor and Francis.
Openshaw, S. & Wymer, C. 1994. Classifying and regionalizing census data. In S. Openshaw, Census Users Handbook (pp. 239-270). Cambridge, UK: Geo Information International.
Painho, M. Vasconcelos, L. Fonseca, J. Geirinhas J. 1997. The Clustering of Urban Environment: the Case of Lisbon. In João Reis Machado & Jack Ahern, Environmental Challenges in an Expanding Urban World and the Role of Information Technologies. CNIG.
Plane, D. & Rogerson, P. 1994. The Geographical Analysis of Population with Application to Planning and Business, John Wiley & Sons, Inc.
Sato, M. & Sato, Y. & Jain, L. C. 1997. Fuzzy Clustering Models and Applications Springer-Verlag: New York.
Schaffer, C., & Green, P. 1998. Cluster-based market segmentation: some further comparisons of alternative approaches. Journal of the Market Research Society, Volume 40 Number 2 April, 155-163.
Wall, M. 1996. Galib: A C++ Library of Genetic Algorithms Components. MIT, http://lancet.mit.edu/ga/