Return to GeoComputation 99 Index
David McKeown and Jeff McMahill
Digital Mapping Laboratory,
Carnegie Mellon University
Pittsburgh, PA 15213 U.S.A.
E-mail: dmm@maps.cs.cmu.edu
E-mail: jmcm@maps.cs.cmu.edu
Douglas Caldwell
U.S. Army Topographic Engineering Center, 7701 Telegraph Road, Alexandria, VA 22315 U.S.A.
E-mail: caldwell@tec.army.mil
The aim of this research was to reduce the time needed to create virtual worlds by improving the line simplification operation in the production process. Direct application of a Douglas-Peucker algorithm for simplification resulted in the generation of topological and terrain-related anomalies that required manual identification and correction. Carnegie Mellon University added automated checks added to the basic Douglas-Peucker algorithm to prevent the most common anomalies. Topological checks stopped lines from intersecting themselves or moving too close to adjacent features. Terrain-related checks ensured that the relationships of the feature data and underlying terrain were preserved during the simplification process. This paper describes the implementation of the topological and terrain checks and demonstrates the improved results by using spatial context in line simplification.
Generalization is used for decluttering maps for presentation at smaller scales, for reducing the information content of digital data representations regardless of scale, and for compressing volumes of spatial data (McMaster and Shea, 1992, Muller, et al., 1995). Automated generalization has been an active topic of research since the 1960's, when Tobler (Tobler, 1966) and Lang (Lang, 1969) proposed line simplification algorithms that reduced the number of vertices required to define a line. Their research was the first of many alternative algorithms for line simplification (Ramer, 1972, Duda and Hart, 1973, Douglas and Peucker, 1973, Reumann and Witkam, 1974, Jenks, 1981, Opheim, 1982, Chrisman, 1983, and Buttenfield, 1985, Deveau, 1985, and Roberge, 1985). This body of research, from the 1960's through the 1980's, focused on the manipulation of the geometry of individual lines, without taking into account the spatial context of simplification.
The automation of other generalization transformations, such as aggregation, amalgamation, exaggeration, merging, collapse, refinement, enhancement, and displacement (McMaster and Shea, 1992), was pursued during the same period, but proved considerably more complicated to address than simplification. The work on individual algorithms evolved into research on expert systems, which integrated multiple generalization transformations. These expert systems would assess a generalization problem, identify appropriate generalization transformations, and apply the transformations to the data (Armstrong, 1991, McMaster, 1991, and Shea, 1991). Because of the difficulties in developing working systems based on an expert-based, fully automated approach, recent emphasis has been placed on augmenting the cartographer's tools in computer-assisted environment. (Weibel, 1991, Bundy, et al., 1995, Muller et al., 1995, Keller, 1995).
Recent research has emphasized the use of context in generalization (Bundy, et al., 1995) and this paper extends this trend research thrust. It builds on earlier line simplification research, but augments the earlier approaches by accounting for the topological relationships among multiple features and the relationship of the feature data with the underlying terrain. This work was not part of a research effort on generalization per se, but arose from needs of a specific application, virtual world construction.
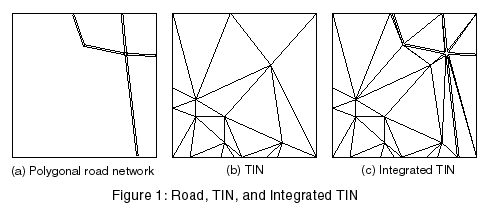
Virtual worlds, which are fully symbolized 3-D databases, provide a series of unique challenges in database construction. These virtual worlds often contain integrated feature and elevation data in the form of a Triangulated Irregular Networks (TIN). Figure 1 shows a simple example of road network polygons, a corresponding bare earth TIN, and the final integrated TIN after their combination.
|
|
While 3-D feature and elevation data is ideal for database construction, it is generally not available. Typical source data consists of 2-D feature data and a 2.5-D digital elevation models (DEM). Simulation databases for virtual worlds require a low information density to support real-time, distributed rendering and display. Unfortunately, the currently available source data for this work within the military includes highly detailed centerline feature data, such as National Imagery and Mapping Agency (NIMA) Feature Foundation Data (FFD), Vector Map (VMAP), or Digital Topographic Data (DTOP). The source data are intended for map production and/or terrain analysis, not simulation. It contains too much detail for direct use in many simulators. Figure 2 shows a section of the original Camp Pendleton DTOP along with the same data simplified to 20 meters. Over the whole dataset, about 74 percent of the segments were removed.
|
|
The virtual world production process originally involved the use of standard geographic information system (GIS) tools for selection and simplification. Selection remains a manual process, which is heavily dependent on Subject Matter Experts (SME), who are familiar with the key terrain and intended use of the simulation database. Simplification is a semi-automated process done using commercial software employing the Douglas-Peucker algorithm. Both linear features, such as roads, and polygon boundaries, such as lake shorelines, are simplified. Unfortunately the use of the basic Douglas-Peucker algorithm resulted in data with topological errors and unrealistic representations of features with regard to the underlying terrain. The resulting errors increased simulation database production timelines and required operator intervention to identify and correct the problems. The solution to the data editing requirement was the development of intelligent algorithms that prevented the errors from occurring by considering spatial context when performing simplification. These algorithms are built around an existing line simplification algorithm, the Douglas-Peucker algorithm (Douglas and Peucker, 1973), but provide additional tests and checks to enhance the performance of the algorithm. The research, conducted by the Digital Mapping Laboratory at Carnegie Mellon University (CMU), addressed simulation database generation problems with the development of topologically-aware and terrain-aware line simplification algorithms.
The topologically-aware simplification algorithms preserve the relationships of the source data in the generalized data. They prevent the insertion of new intersections in the linear data, and perform proximity checks to keep features user-specified distances apart in the simplified output. The terrain-aware simplification algorithms preserve relationships with features and the underlying terrain, preventing roads from going over hills when they lie around hills in the source data.
Carnegie Mellon University researchers first addressed the problem of topological errors in the simplification process. The Douglas-Peucker, which was used in production, contained no error checks on the simplified linear features. It was possible to create simplified features that crossed themselves or nearby features. Carnegie Mellon University researchers developed self-intersection checks and proximity checks.
The proximity checks are essential and somewhat unique to the simulation database construction process. Linear features, such as roads, are converted from centerlines to polygons in the simulation database. Roads with widths and elevations are displayed in the virtual world. Because the centerline features are converted to areal features, it is possible for road polygons to overlap in the simulation database when they are generated from non-overlapping centerlines. Researchers at CMU developed proximity checks to prevent the overlapping polygonal features.
Generalization at CMU is based on a data format called for Boundary REPresentation (BREP). BREP is a 2.5-D, topologically-consistent format. All intersections are explicitly marked, and all objects are connected to neighboring objects. When data are converted to BREP or as existing data are changed, these requirements are held true. For example, if an edge is added that would intersect an existing feature, it will be split into two edges, and a node created at the intersection point.
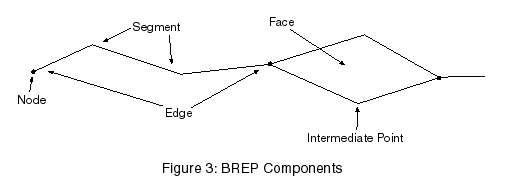
A BREP is made up of three basic object types, nodes, edges, and faces, as shown in Figure 3. A node is simply a point feature. It can either be disconnected, or attached to an edge. An edge is a connected set of intermediate points with a node at each end. A face is a closed region bounded by edges. (The only exception to this is the "outside face," which is defined to be the area not contained in any other faces. As such, it is neither closed nor bounded.) Each object type has a list of attributes associated with it. When data are imported from ITD, DTOP, or other formats, the attribution from the original data is preserved.
|
|
An additional feature of BREP is the underlying two-D hash table. It is used to greatly speed up searches and other operations. This, combined with the other features of BREP, allows many of the simplification improvements to have reasonable runtime when they would have been unthinkable with other data formats.
A BREP file can be viewed as having several components relevant to simplification, features, edges, and segments. A feature is the highest level, and is something like a road or a river. A feature can be made up of one or more edges. Edges are as described above. A segment is simply a straight line between two points in an edge. In some cases we refer to a simplified segment. This is simply a segment in a simplified edge that corresponds to one or more segments in the original data.
Simplification using BREP will not change the number of features or edges, except in some cases where very small areal features can be reduced to point features. The number of segments, however, will be reduced, as that is the main goal of simplification. The current BREP simplification algorithm is a distanced-based algorithm based on the Douglas-Peucker algorithm. The algorithm works by determining a subset of the points that will cause no part of the simplified feature to be outside of a corridor determined by the distance tolerance. No points are moved from their original location, and the endpoints always are left alone.
The intersection check is simply implemented by doing the normal simplification and then using BREP functions to check for any intersections that were created. If there are no new intersections, the simplified edge is kept. Otherwise, the simplified segment that intersects is replaced with the corresponding original part of the edge. Since there were no intersections in the original section of edge (as guaranteed by BREP), this fixes the problem.
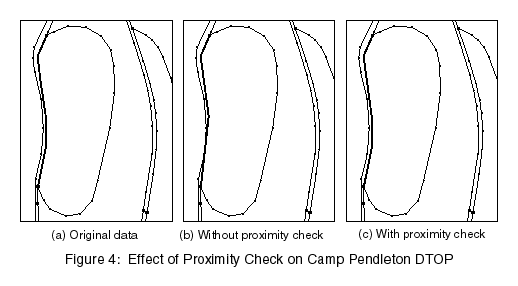
The proximity check is implemented in much the same way as the intersection check. The edge is simplified and then the check is performed. As with the intersection check, if a problem is detected for a segment, it is replaced with the original data. An additional check is performed first, however, to determine the proximity of the original data. If the original data already had a proximity problem and the simplification did not make it worse, the simplified segment is kept. Figure 4 shows a simple proximity check example. The highlighted edge is simplified to 15 meters, and a proximity problem is created. The proximity check is turned on and set to 5 meters, and the problem goes away.
|
|
It is important to note that the proximity check does not incorporate displacement algorithms and does not correct problems with the unsimplified source data. For example, two centerline features may be so close together in the unsimplified data that they overlap when converted to polygons. The proximity check can identify this overlap, but it does not separate the features. It will still try to simplify the data, but only if it can do so without making the overlap worse. The proximity check merely prevents increased overlap as a result of the simplification process.
The topologically-aware simplification algorithm reduced the amount of manual editing required for the Camp Pendleton DTOP by 17 actual intersections, and 267 proximity intersections.
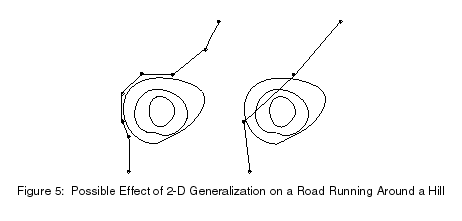
Topologically-aware simplification addresses the issue of errors introduced in the 2-D topology of the simplified linear features. Applying 2-D simplification algorithms without regard to the underlying terrain causes an equally important 3-D problem in the generation of virtual worlds. For example, a road may pass around a hill. If the road is simplified, its relationship to the hill may change, so instead of going around the hill, the road now goes directly up and over the hill, as shown in Figure 5.
|
|
If the simplified road is pasted on the terrain in the virtual world, it may have an unrealistically high slope that would not be found in the real world. An automatic cut and fill routine applied to the simplified road could create a severe cut through the hill, which is equally unrealistic. The severe cuts are termed "killer cuts" in a virtual world, because they can disable a vehicle traveling cross country. This is caused by a vehicle 'crashing' when falling down a steep slope. Figure 6 from the Synthetic Theater of War - Europe (STOW-E) database illustrates the danger of "killer cuts."
|
|
The problem created by the simplified road can only be corrected by manually editing the road to make it once again go around the hill. Because 2-D simplification algorithms introduced anomalies that required time-consuming corrections, researchers at Carnegie Mellon University developed two alternative terrain-aware enhancements to the line simplification process.
The terrain-aware algorithms both require a DEM to supply elevation information about the underlying terrain. Elevations for points are simply looked up in the DEM as they are needed. It is not possible to use elevations solely from the BREP data even if they are available. This is because these algorithms need to examine elevations outside of the original data.
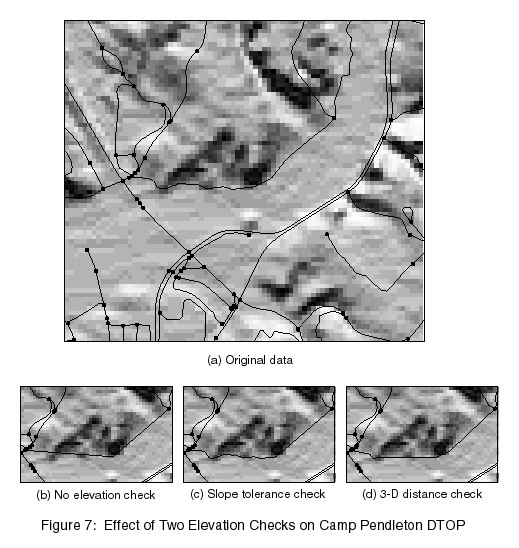
The first elevation check is based on a slope tolerance. The average slope of each simplified segment is compared to the average slope of that section of the edge before simplification. The slope is computed using values from a DEM. If the difference between the two is greater than the tolerance, that segment is replaced with the original data. The first elevation check should always prevent the slope from changing more than the tolerance value; however, in some cases it will end up not simplifying the edge at all, or very little. Figure 7 shows the effect of the slope tolerance check. In this case, about half of the edge had to be replaced with the original data to fix the problem.
|
|
The second elevation check extends the simplification distance check to 3-D, getting the elevation values from a DEM. In this case, an elevation weight can be specified to increase or decrease the effect of elevation changes; a point that was previously within the tolerance in 2-D, but on a steep hill, would now be outside the tolerance. The second check seems to provide better simplification results, but can easily miss elevation changes that do not lie on points in the edge. Figure 7 shows the effect of the 3-D distance check, as compared to the slope tolerance check. In this case it clearly performed much better.
The slope tolerance topologically-aware simplification algorithm reduced the amount of manual editing required for the Camp Pendleton DTOP by 195 terrain intersections. Because of the integration of the elevation weight algorithm, there is no direct way to evaluate the number of terrain intersections that were prevented in this case.
The line simplification research described in this paper was undertaken to improve the virtual world database production process. The previous use of a commercial implementation of the Douglas-Peucker algorithm resulted in topological and terrain-related artifacts in the simplified data. The artifacts impacted production timelines by requiring manual intervention for identification and correction of the artifacts.
Carnegie Mellon University researchers enhanced the basic Douglas-Peucker algorithm to incorporate topology checks for self-intersection and proximity, as well as terrain checks to ensure that the relationships of the features and underlying terrain were preserved in the production process. The checks proved effective at eliminating the targeted artifacts and reduced the overall amount of manual editing required in the production process. While developed specifically for use in a virtual world production environment, the topological and terrain-aware checks can be applied with other simplification algorithms and in other application environments.
The Carnegie Mellon University (CMU) research on line simplification was supported by the Defense Advanced Research Projects Agency (DARPA), the Defense Modeling and Simulation Office (DMSO), and the National Imagery and Mapping Agency (NIMA)/Terrain Modeling Project Office (TMPO) under Contract DACA76-95-C-009 to the U.S. Army Topographic Engineering Center (TEC). The views and conclusions contained in this report are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of DARPA, DMSO, NIMA/TMPO, TEC, or the United States Government.
Armstrong, M.P., 1991. 'Knowledge classification and organization.' In B.P. Buttenfield and R.B. McMaster (Eds.), Map generalization: Making rules for knowledge representation. London: Longman Scientific and Technical, pp. 86-102.
Brassel K. E. and R. Weibel, 1988. 'A review and conceptual framework of automated map generalization.' International Journal of Geographical Information Systems, 2(3). pp. 229-244.
Bundy, G. L., C.B. Jones, and E. Furse, 1995. 'Holistic generalization of large-scale cartographic data.' In J.C. Muller, J.P. Lagrange and R. Weibel (Eds.), GIS and generalization: methodology and practice. London: Taylor and Francis, Ltd., pp. 106-119.
Buttenfield, B.P., 1985.'Treatment of the cartographic line.' Cartographica, 22(2), pp. 1-26.
Chrisman, N.R., 1983. 'Epsilon Filtering: a technique for automated scale changing.' In Technical Papers, 43rd Annual ACSM Meeting. Washington, D.C.: American Congress on Surveying and Mapping, pp. 322-331.
Cromley, R. G., 1991. 'Hierarchical methods of line simplification.' Cartography and Geographic Information Systems, 18(2), pp. 125-131.
Deveau, T.J., 1985. 'Reducing the number of points in a plane curve representation.' In Proceedings of the Seventh International Symposium on Automated Cartography, AUTO-CARTO VII. Falls Church, VA: American Society of Photogrammetry and the American Congress on Surveying and Mapping, pp. 152-160.
Douglas, D.H. and T.K. Peucker, 1973. 'Algorithms for the reduction of the number of points required to represent a digitized line or its character.' The Canadian Cartographer, 10(2), pp. 112-123.
Duda, R. and P. Hart, 1973. Pattern Classification and Scene Analysis. New York: John Wiley and Sons, Inc.
Jenks, G.F., 1981. 'Lines, computers, and human frailties.' Annals of the Association of American Geographers, 71(1), pp. 1-10.
Keller, S. F., 1995. 'Potentials and limitations of artificial intelligence techniques applied to generalization.' In J. C. Muller, J. P. Lagrange and R. Weibel, Eds., GIS and generalization: methodology and practice. London: Taylor and Francis, Ltd., pp. 135-147.
Lang, T., 1969. Rules for robot draughtsmen. The Geographical Magazine, 42(1), pp. 50-51.
McMahill, J. D., 1998. Interactive generalization user's guide. Pittsburgh, PA: Carnegie-Mellon University.
McMaster, R. B., 1991. 'Conceptual frameworks for geographical knowledge.' In B. P. Buttenfield and R. B. McMaster, Eds., Map generalization: Making rules for knowledge representation. London: Longman Scientific and Technical, pp. 21-39.
McMaster, R. B. and K.S. Shea, 1992. Generalization in digital cartography. Washington, D.C., U.S.: Association of American Geographers.
Muller, J. C., R. Weibel, J.P. Lagrange, and F. Salge, 1995. 'Generalization: State of the art and issues.' In J. C. Muller, J. P. Lagrange and R. Weibel, Eds., GIS and generalization: methodology and practice. London: Taylor and Francis, Ltd., pp. 3-17.
Opheim, H., 1982. 'Fast reduction of a digitized curve.' Geo-Processing, 2, pp. 33-40.
Ramer, U., 1972. 'An iterative procedure for the polygonal approximation of plane curves.' Computer Graphics and Image Processing, 1, pp. 244-256.
Reumann, K. and A.P.M. Witkam, 1974. 'Optimizing Curve Segmentation in Computer Graphics.' International Computing Symposium. Amsterdam: North-Holland Publishing Company. pp. 467-472.
Roberge, J., 1985. 'A data reduction algorithm for planar curves.' Computer Vision, Graphics, and Image Processing, (29). pp.168-195
Shea, K.S., 1991. 'Design considerations for an artificially intelligent system.' In B. P. Buttenfield and R.B. McMaster (Eds.), Map generalization: Making rules for knowledge representation, London: Longman Scientific and Technical, pp. 3-20.
Tobler, W.R., 1966. 'An Experiment in the Computer Generalization of Maps.' Technical Report No. 1, Office of Naval Research Task No., Contract No. 1224 (48) Washington, D.C.: Office of Naval Research, Geography Branch, pp. 389-137.
Weibel, R., 1991. 'Amplified intelligence and rule-based systems.' In B. P. Buttenfield and R. B. McMaster Eds., Map generalization: Making rules for knowledge representation. London: Longman Scientific and Technical, pp.172-186.